







В январе стали известны случаи массовых продаж бывших в употреблении жестких дисков Seagate под видом новых. С тех пор проблема не утратила актуальности: мошенники продолжают придумывать новые способы выдачи б/у оборудования за новое.
На продажи бывших в употреблении накопителей Seagate под видом новых впервые обратило внимание издание Tom’s Hardware Guide.
Изначально злоумышленники заменяли заводские наклейки и подделывали данные SMART (технология самоконтроля и анализа состояния дисков).
Выявить такие подделки удалось только с помощью специализированных диагностических инструментов, предназначенных для анализа состояния жестких дисков.
Недавно немецкое издание Heise сообщило о появлении новой схемы мошенничества: злоумышленные продавцы научились обходить ранее эффективные методы диагностики. Теперь они манипулируют не только данными SMART, но и метриками, используемыми ранее для выявления подделок. Таким образом, прежние способы диагностики, применявшиеся в январе, больше не дают гарантированного результата.
Наибольшее распространение подобные схемы получили среди жестких дисков формфактора 2,5 дюйма, ёмкостью от 4 до 20 Тбайт, используемых преимущественно в системах хранения данных.
Эксперты рекомендуют обращать внимание на признаки, позволяющие заподозрить контрафактную продукцию. В частности, на оригинальных дисках всегда присутствует фирменная наклейка на лицевой стороне. Её отсутствие может указывать на подделку.
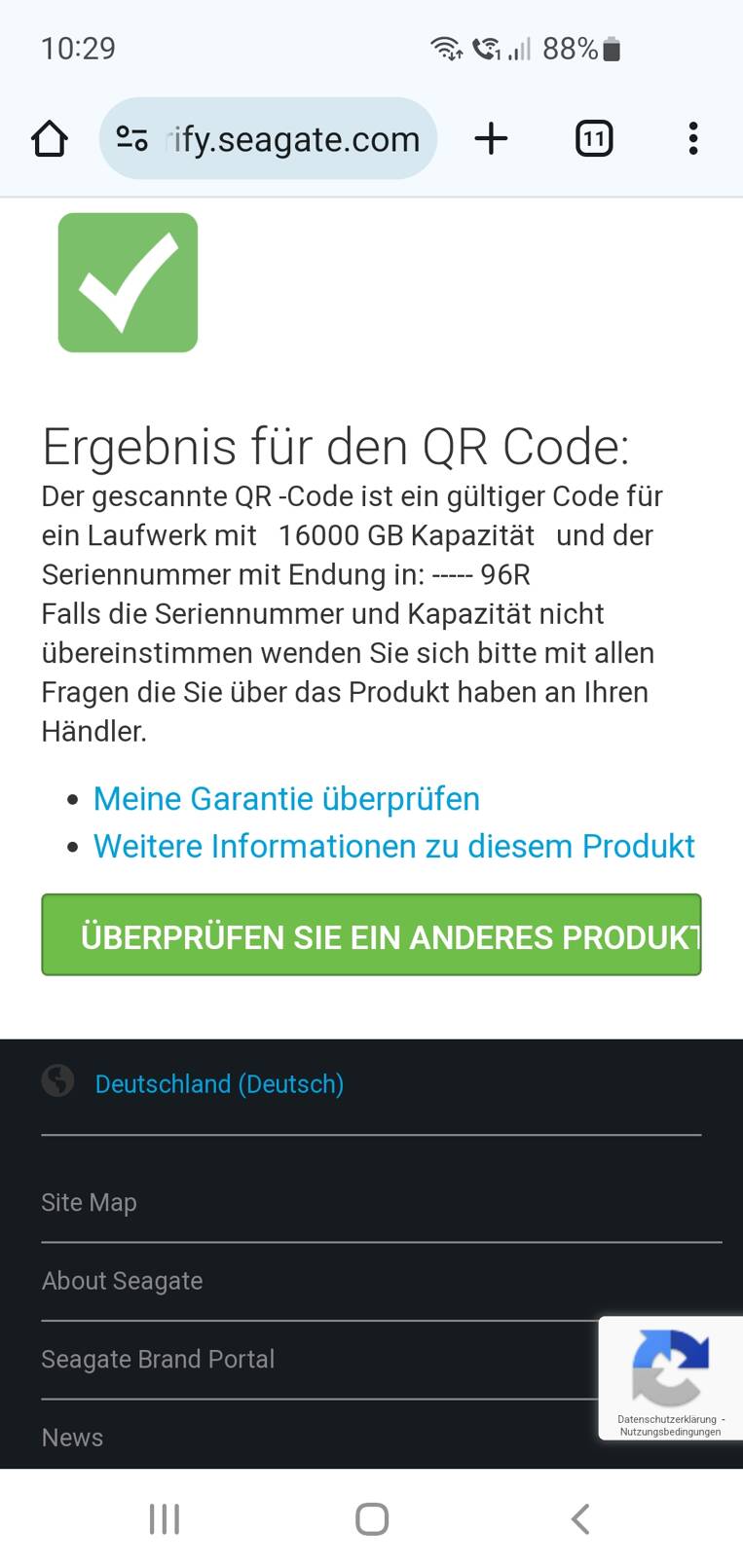
Кроме того, при считывании штрихкода с подлинного накопителя пользователя автоматически перенаправляет на официальный сайт гарантийного обслуживания. У поддельных дисков такая функция, как правило, отсутствует.
Не так давно мы приводили интересную статистику: 42% бывших в употреблении жестких дисков, продаваемых на площадке eBay, содержат персональные данные.






