















МВД хочет разрешить внесудебную блокировку сайтов и страниц, на которых продают активированные сим-карты, чужие аккаунты и другие инструменты для мошенников. Инициатива вошла в обсуждаемый пакет «Антифрод 3.0». Роскомнадзор идею пока встретил без аплодисментов.
Без решения суда предлагается закрывать доступ к ресурсам с объявлениями о продаже данных для входа в платёжные сервисы, средств аутентификации, электронных подписей, а также регистрационных документов компаний и ИП.
Под блокировку могут попасть и площадки, предлагающие обмен цифровых валют, выяснили «Известия».
В МВД объясняют: такая торговля помогает совершать преступления, а ответственность за неё уже предусмотрена УК. Значит, ждать судебного решения для удаления каждого объявления ведомство считает излишней роскошью.
Роскомнадзор возражает, что новые полномочия потребуют денег, сотрудников и других ресурсов. Ведомство попросило оценить количество потенциальных блокировок и доказать, что действующих механизмов — через суд или Генпрокуратуру — действительно недостаточно.
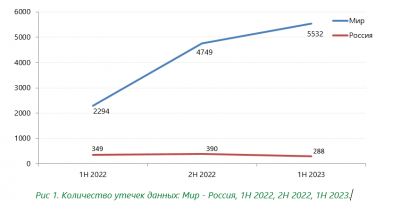
Масштаб серого рынка внушительный. По экспертным оценкам, в открытом Рунете размещено не менее 500 тыс. актуальных предложений о продаже симок, аккаунтов и связанных услуг.
Исследование Open Measures за год обнаружило в Telegram свыше 5 млн публикаций о покупке и продаже аккаунтов. В базе ЦБ в 2025 году числилось около 1,2 млн счетов дропов против 700 тыс. годом ранее.
Эксперты считают, что быстрая блокировка усложнит поиск подставных номеров, счетов и аккаунтов, повысив стоимость входа в мошеннический бизнес. Но полностью рынок не исчезнет: продавцы переедут в закрытые чаты, даркнет и на зеркала.
Поэтому законодателям советуют чётко описать признаки незаконного объявления. Иначе вместе с лавкой готовых симок под раздачу рискуют попасть легальные сервисы. Пока же окончательное решение не принято, пакет «Антифрод 3.0» проходит межведомственное согласование.



