














Мошенники нашли красивую упаковку для старой схемы: берут известный бренд, рисуют фейковую страницу Google Play, запускают рекламу в соцсетях и под видом официального приложения ведут пользователя в онлайн-казино. В объявлениях злоумышленники используют названия и визуальный стиль известных компаний, включая Tesco, Amazon, Monzo, Revolut и стриминговые сервисы.
По данным Netcraft, кампания продвигается через платную рекламу в Facebook, Instagram, Threads (все три принадлежат корпорации Meta, признанной экстремистской и запрещённой в России) и TikTok.
Где-то всё выглядит примитивно — просто «Brand Slots». А где-то уже почти спектакль: поддельные интерфейсы, фальшивые отзывы, липовые данные из магазинов приложений и даже ИИ-видео с якобы сотрудниками бренда.
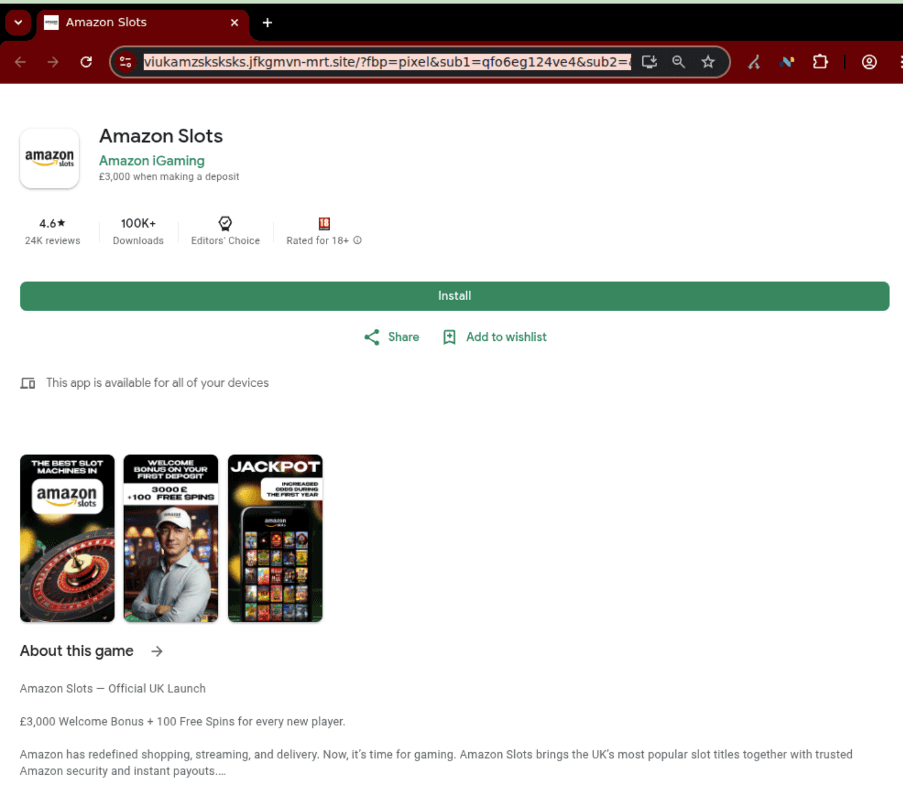
Главная легенда — официальный запуск слотов или казино-приложения от известной компании. Пользователь кликает по рекламе и попадает на страницу, похожую на Google Play, App Store или сайт бренда. Но кнопка «Install» не ведёт в настоящий магазин приложений. Вместо этого браузер предлагает добавить на главный экран PWA — прогрессивное веб-приложение.
После установки такая штука выглядит как обычное приложение: с иконкой, названием и оформлением под бренд. На деле это тонкая обёртка, которая открывает сторонний сайт онлайн-казино. То есть пользователь думал, что ставит «Amazon Slots» или «Monzo Slots», а получил ярлык на азартную площадку.
Netcraft считает, что схему подпитывает партнёрская экономика. В PWA и ссылках есть параметры, которые позволяют отслеживать регистрации и депозиты. По открытым данным, выплаты за игрока, внесшего депозит, могут составлять от $50 до $350. С такими ставками мошенникам есть смысл вкладываться в правдоподобные объявления и массовый запуск рекламы.
В некоторых кампаниях использовались фейковые страницы с вымышленными разработчиками, скачиваниями и отзывами. Были и интерактивные приманки вроде колеса удачи с гарантированным выигрышем, после которого пользователя просили установить PWA, чтобы забрать приз.
Опасность здесь не только в потерянных деньгах. Такие PWA размывают границу между настоящим приложением и подделкой: браузерная оболочка минимальна, и всё выглядит почти как фирменный сервис. Только фирменного там — разве что украденный логотип.



