







26 января 2017 года, разработчики одной из популярнейших CMS в мире выпустили WordPress 4.7.2, сообщив, что в новой версии платформы был исправлен ряд проблем. Как выяснилось неделю спустя, релиз WordPress 4.7.2 устранил крайне серьезную уязвимость, связанную с повышением привилегий.
В конце января 2017 года брешь обнаружили специалисты компании Sucuri, и они описывают ее как неавторизованную эскалацию привилегий через REST API. Уязвимости подвержены версии 4.7.0 и 4.7.1.
Тогда раскрытие данных об уязвимости сознательно отложили на неделю, чтобы как можно больше сайтов успели спокойно установить обновление, но, судя по всему, это не слишком помогло. Специалисты Sucuri сообщают, что первые попытки эксплуатации бага были замечены в тот же день, когда информация о проблеме была опубликована. В настоящий момент количество атак продолжает расти и уже превысило отметку 3000 дефейсов в день,
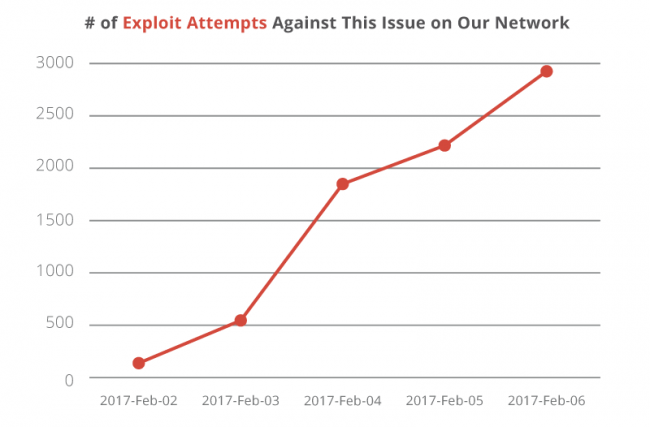
Напомню, что проблема позволяет неавторизованному атакующему сформировать специальный запрос, при помощи которого можно будет изменять и удалять содержимое любого поста на целевом сайте. Кроме того, используя шорткоды плагинов, злоумышленник может эксплуатировать и другие уязвимости CMS, которые обычно недоступны даже пользователям с высокими привилегиями. В итоге атакующий может внедрить на страницы сайта SEO-спам, рекламу, и даже исполняемый PHP-код, все зависит от доступных плагинов.
Аналитики Sucuri пишут, что их собственные серверы-ловушки (honeypot) обнаружили уже четыре группы атакующих, которые активно эксплуатируют свежую проблему WordPress. В блоге компании приведена следующая статистика:
| Название группы | IP-адреса | Число жертв |
| w4l3XzY3 | 176.9.36.102 185.116.213.71 134.213.54.163 2a00:1a48:7808:104:9b57:dda6:eb3c:61e1 (IPv6) |
66 000 |
| Cyb3r-Shia | 37.237.192.22 | 500 |
| By+NeT.Defacer | 144.217.81.160 | 500 |
| By+Hawleri_hacker | 144.217.81.160 | 500 |
К сожалению, на данный момент ситуация ухудшилась. Так, простой поиск по названию группировки w4l3XzY3 показывает, что компрометации подверглись более 100 000 сайтов:
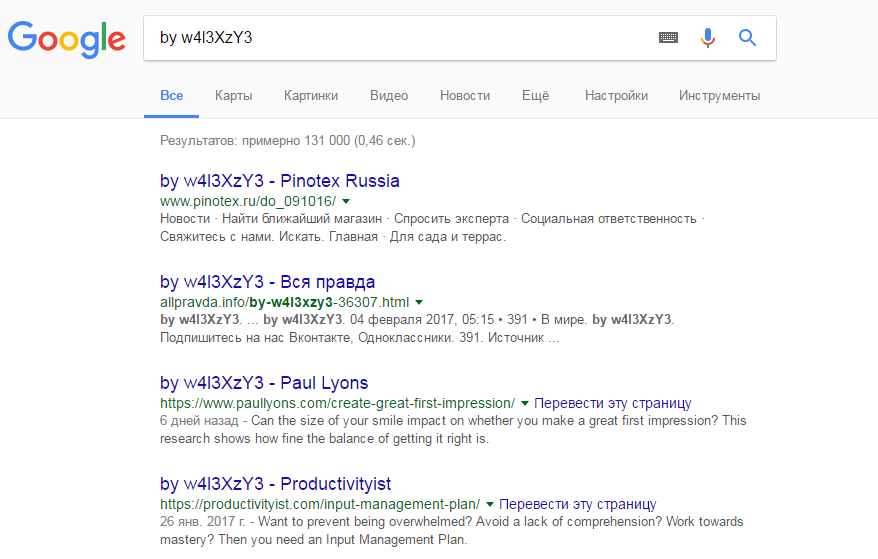
Исследователи пишут, что пока проблему эксплуатируют преимущественно скрипт-кидди, которые скорее развлекаются, чем пытаются нанести реальный вред. Однако специалисты ожидают, что в скором времени злоумышленники будут пытаться монетизировать баг.
«Мы уже наблюдали несколько попыток эксплуатации проблемы, в ходе которых [атакующие] пытались добавлять спамерские изображения и контент в посты. Учитывая возможность монетизации, скорее всего, это станет самым популярным вектором использования уязвимости», — пишут аналитики Sucuri






