







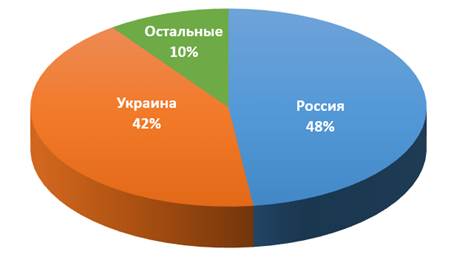
Эксперты вирусной лаборатории ESET в Братиславе (Словакия) обнаружили новые модификации трояна-вымогателя Simplocker, атакующего мобильные устройства на базе Android. По данным облачной технологии ESET LiveGrid, наибольшее распространение троян получил в России и Украине.
Simplocker – первый троян-вымогатель для смартфонов и планшетов на Android, способный шифровать файлы пользователя. Он блокирует доступ к устройству и требует за расшифровку денежный выкуп.
География заражения Simplocker
Новые модификации Simplocker, обнаруженные аналитиками ESET, отличаются друг от друга рядом признаков:
- некоторые варианты используют для связи с командным сервером обыкновенные домены, другие – домены .onion, принадлежащие анонимной сети TOR;
- обнаружены различные пути передачи команды decrypt, которая сигнализирует о факте получения выкупа злоумышленниками;
- используются разные интерфейсы окон с требованием выкупа и различные валюты (рубль и гривна);
- некоторые модификации используют в сообщении о блокировке фотографию пользователя, сделанную на встроенную камеру устройства;
- вопреки обещанию мошенников, несколько версий Simplocker не шифруют файлы, а просто блокируют устройство.
Вместе с этим в большинстве модификаций используется упрощенный подход к шифрованию с использованием алгоритма AES и жестко зашитого ключа.
Система телеметрии ESET LiveGrid позволила установить основные векторы заражения Simplocker. Чаще всего злоумышленники маскируют троян под приложение с порнографическим контентом или популярную игру, например, Grand Theft Auto: San Andreas.
Simplocker распространяется также посредством загрузчика (downloader), который удаленно устанавливает основной файл трояна. Использование этого типа вредоносного ПО является обычной практикой для Windows, но в последнее время такие программы создаются и для Android.
Специалисты ESET изучили один из загрузчиков, который детектируется продуктами ESET NOD32 как Android/TrojanDownloader.FakeApp. Он распространялся под видом видеоплеера USSDDualWidget через магазин приложений. Его URL-адрес не указывал напрямую на вредоносный файл с трояном, поэтому загрузчик не вызывал подозрений. Установка Simplockerосуществлялась после перенаправления на другой сервер, находящийся под контролем злоумышленников.
«Подобные приложения могут появляться даже на Google Play и успешно избегать разоблачения со стороны security-приложений, в частности, Bounce, - комментирует Артем Баранов, ведущий вирусный аналитик ESET Russia. – Причина в том, что такие загрузчики при установке не требуют подозрительных разрешений на доступ, а сам факт перехода по URL еще не говорит о вредоносной активности».






