







При разборе январских атак APT37 эксперты AhnLab обнаружили, что арсенал северокорейских хакеров пополнился бесфайловым зловредом M2RAT. Чтобы скрыть полезную нагрузку, злоумышленники используют стеганографию, да и сам троян старается оставлять как можно меньше следов в системе.
Кибергруппа APT37, известная также как RedEyes, ScarCruft , Reaper и Ricochet Chollima, занимается шпионажем — как многие считают, при поддержке властей КНДР. В прошлом году, по данным BleepingComputer, злоумышленники активно использовали уязвимость 0-day в Internet Explorer (CVE-2022-41128) для доставки различных вредоносов.
Так, например, в ходе атак на европейские организации APT-группа через эксплойт устанавливала бэкдор Dolphin для мобильных устройств. Российским дипломатам она пыталась навязать кастомного RAT-трояна Konni, американским журналистам — персональные варианты Goldbackdoor (PDF).
Новобранец M2RAT был обнаружен при анализе писем с вредоносным вложением, которые APT37 избирательно разослала в прошлом месяце. При открытии маскировочного документа срабатывает эксплойт CVE-2017-8291 (к RCE-уязвимости GhostButt в текстовом редакторе Hangul, популярном в Корее).
В случае успеха в системе запускается шелл-код, который загружает JPEG-файл и запускает на исполнение вредоносный код, спрятанный в картинке. Чтобы обеспечить себе постоянное присутствие в системе, зловред регистрирует PowerShell-команду, создавая новый ключ реестра Run.
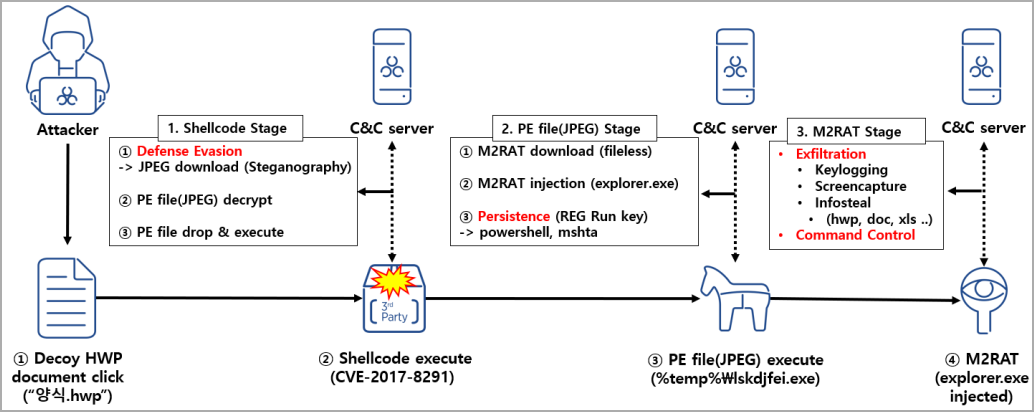
По свидетельству AhnLab, вредонос M2RAT работает как троян удаленного доступа. Он умеет собирать информацию о зараженной системе и отправлять ее на свой сервер, регистрировать клавиатурный ввод, воровать данные, выполнять различные команды, делать снимки экрана (автономно и с заданной периодичностью).
Кроме того, зловред, как и бэкдор Dolphin, проводит сканирование на наличие подключенных к компьютеру портативных устройств. При обнаружении смартфона или планшета проводится поиск документов и аудиозаписей, с копированием на ПК. Украденные данные отсылаются на C2 в виде запароленного RAR-архива, и локальная копия стирается из памяти, чтобы замести следы.
Новоявленный троян также интересен тем, что использует общую память для C2-коммуникаций и эксфильтрации данных. Таким образом, обмен M2RAT с C2-сервером сведен к минимуму, что сильно затрудняет анализ.






