








Более 290 материнских плат от MSI по умолчанию содержат небезопасную настройку UEFI Secure Boot, позволяющую загружать образ операционной системы с некорректной или отсутствующей подписью.
На проблему указал польский исследователь Давид Потоцкий. По его словам, неоднократные попытки связаться с MSI и проинформировать компанию о баге не привели к результату.
Как отметил Потоцкий, проблема затрагивает множество материнских плат от MSI, как на Intel, так и на AMD. Среди проблемных материнок есть и последние модели, использующие актуальную версию прошивки.
Secure Boot — одна из защитных функций, встроенных в прошивку UEFI-плат. Её задача — следить, чтобы только доверенный (подписанный) софт загружался на этапе запуска операционной системы.
Чтобы зафиксировать подлинность ядра, загрузчика ОС и других критически важных компонентов, Secure Boot проверяет PKI (public key infrastructure, инфраструктура открытых ключей). Если софт не подписан или сама подпись была модифицирована, Secure Boot заблокирует загрузку системы.
Давид Потоцкий утверждает, что версия прошивки MSI под номером 7C02v3C, выпущенная 18 января 2022 года, поменяла дефолтные настройки Secure Boot. Теперь ОС загрузится даже в том случае, если были обнаруженные сомнительные компоненты.
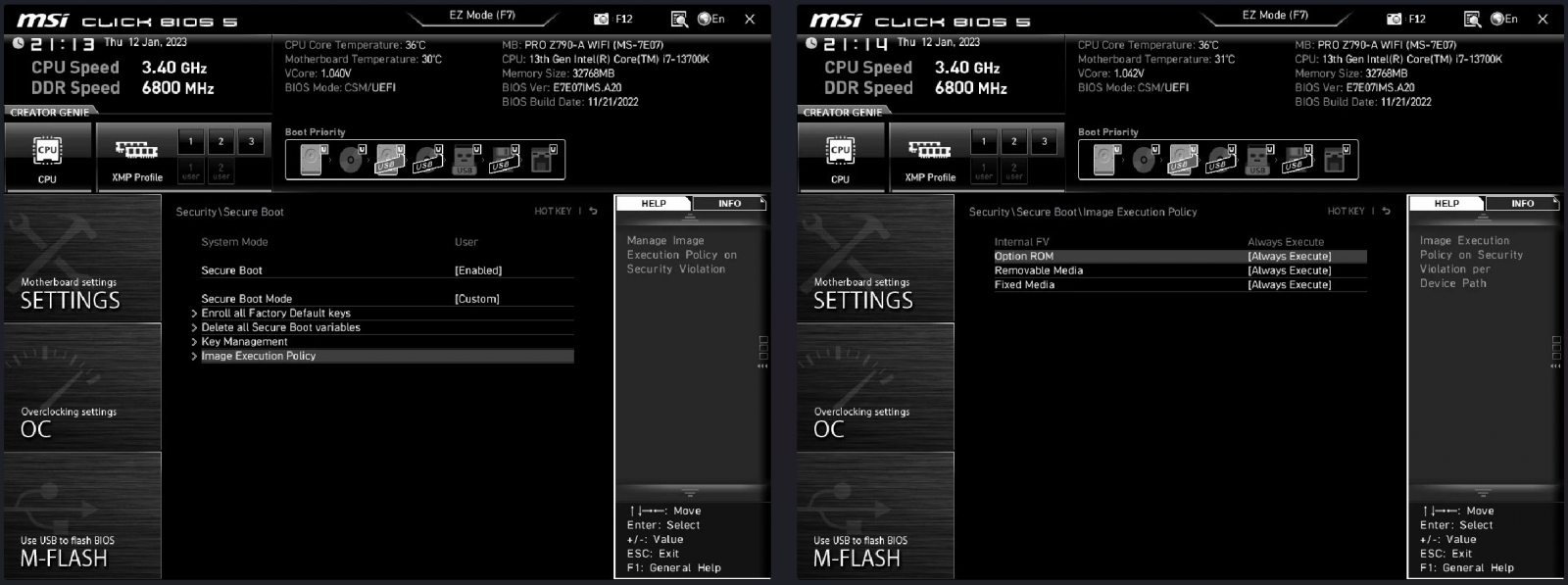
Полный список затронутых материнских плат Потоцкий выложил на GitHub. Пользователям рекомендуют зайти в настройки BIOS и проверить опцию “Image Execution Policy“. Её значение нужно установить на “Deny Execute“.
Напомним, в ноябре геймеры подверглись атаке фейкового MSI Afterburner, который устанавливал на их компьютеры майнеры и троян RedLine.






