








Киберпреступная группировка, распространяющая вымогатель Qlocker, решила свернуть свои операции. Всего за один месяц злоумышленникам удалось заработать $350 тысяч за счёт эксплуатации уязвимостей в сетевых накопителях (NAS) QNAP.
В апреле владельцы NAS-устройств QNAP столкнулись с волной кибератак, в результате которых вместо файлов появились защищённые паролем архивы 7-zip. Также жертвы вредоноса нашли текстовый файл «!!!READ_ME.txt», объясняющий ситуацию и требующий выкуп.
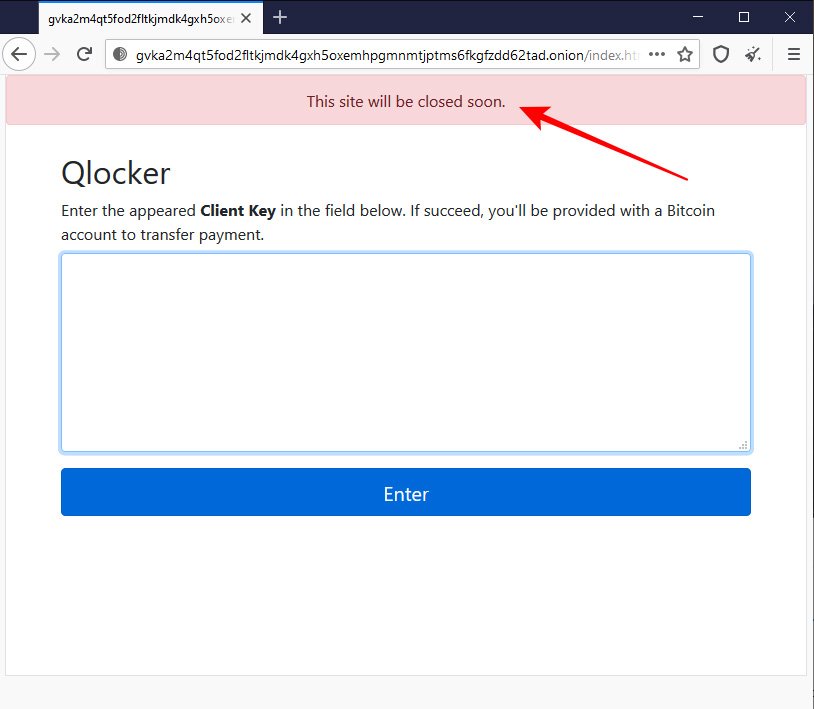
Чтобы вернуть файлы в исходное состояние, пользователи должны были проследовать на сайт в сети Tor. На этом ресурсе владельцу сетевого накопителя объясняли, что его атаковал шифровальщик Qlocker, а за возврат файлов придётся заплатить около $550 в биткоинах.
Позже стало понятно, что киберпреступники использовали в атаках уязвимости, на которые исследователи указывали не так давно. Эти бреши позволяли использовать встроенное приложение 7-zip для шифрования файлов жертвы. При этом злоумышленник мог эксплуатировать их удалённо.
С помощью такого незатейливого подхода преступники смогли поразить более тысячи устройств всего за один месяц. Причём отдельные пользователи утверждали, что злоумышленники действовали непорядочно: после перевода означенной суммы они требовали ещё более $1000 за возврат файлов.
Тем не менее сейчас операторы программы-вымогателя решили остановиться. Например, на их ресурсе висит уведомление:
«Скоро этот сайт будет закрыт».
Как выяснили в BleepingComputer, жертвы заплатили в общей сложности 8,93258497 биткоинов, что равно $353 708.






