








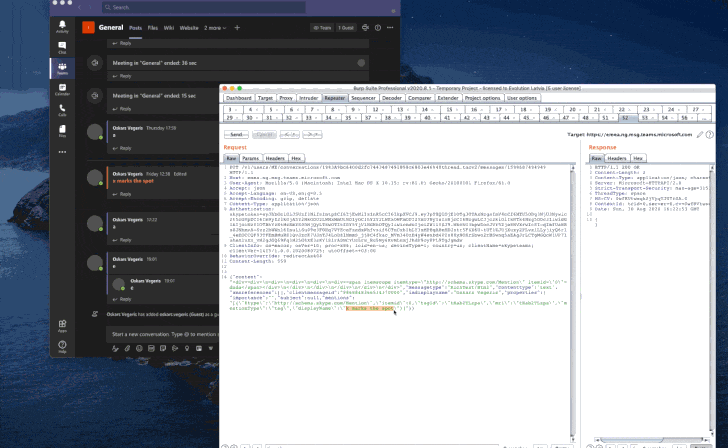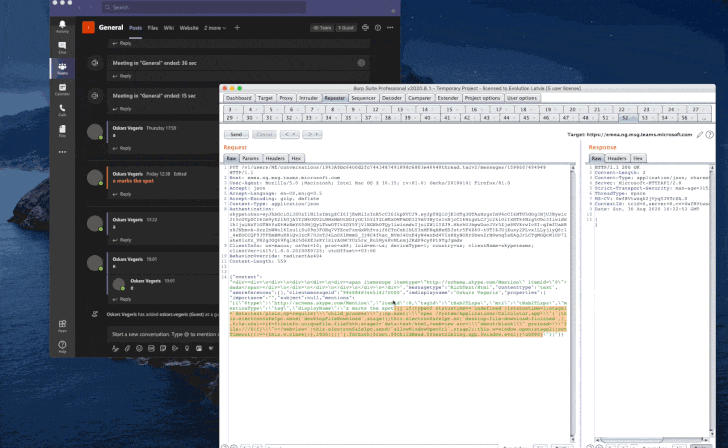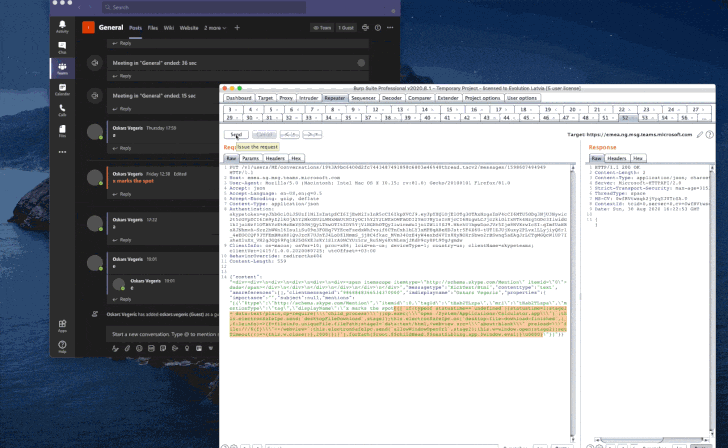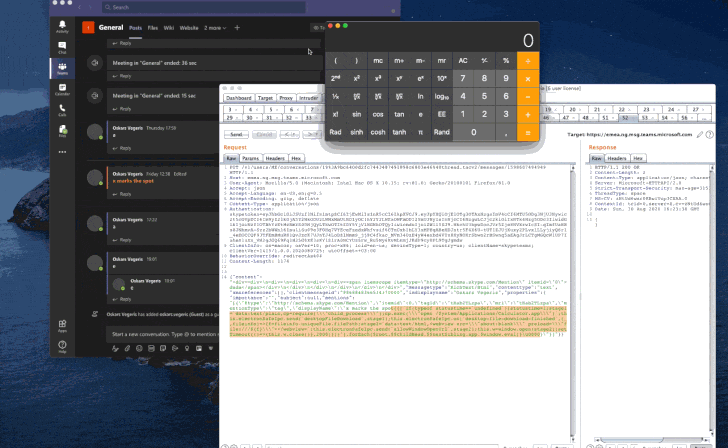







Российские счета основателя Telegram Павла Дурова* должны заблокировать после его включения в перечень террористов и экстремистов Росфинмониторинга. Ограничения распространяются прежде всего на личные финансы и имущество Дурова*.
Об этом РИА Новости сообщил адвокат Дмитрий Рощин. Банки и другие финансовые организации обязаны приостановить операции по его счетам в России.
При этом Telegram не становится автоматически запрещённым или экстремистским ресурсом, уточняют «Известия». Мессенджер и его основатель с точки зрения закона — всё-таки не одно и то же.
С переводами Дурову* ситуация сложнее. Сам факт отправки денег ещё не превращает человека в финансиста терроризма. Для уголовной ответственности потребуется доказать, что средства предназначались именно для террористической деятельности, подчеркнул адвокат.
Росфинмониторинг внёс предпринимателя в перечень 30 июля. Ранее ФСБ предъявила ему обвинение в содействии террористической деятельности и объявила в международный розыск.
По версии ведомства, администрация Telegram не удалила каналы, чаты и боты, которые украинские спецслужбы якобы использовали при подготовке диверсий, терактов, массовых убийств и кибератак в России. Виновным Дурова* пока не признали, это может сделать только суд.
* Внесён Росфинмониторингом в перечень террористов и экстремистов.



