













«Инфосистемы Джет» представила исследование популярных тактик и техник нарушения киберустойчивости российских компаний. В его основу лег опыт реагирования и ликвидации последствий более 100 крупных киберинцидентов, в расследовании которых команда Jet CSIRT принимала участие с 2023 по 2025 год.
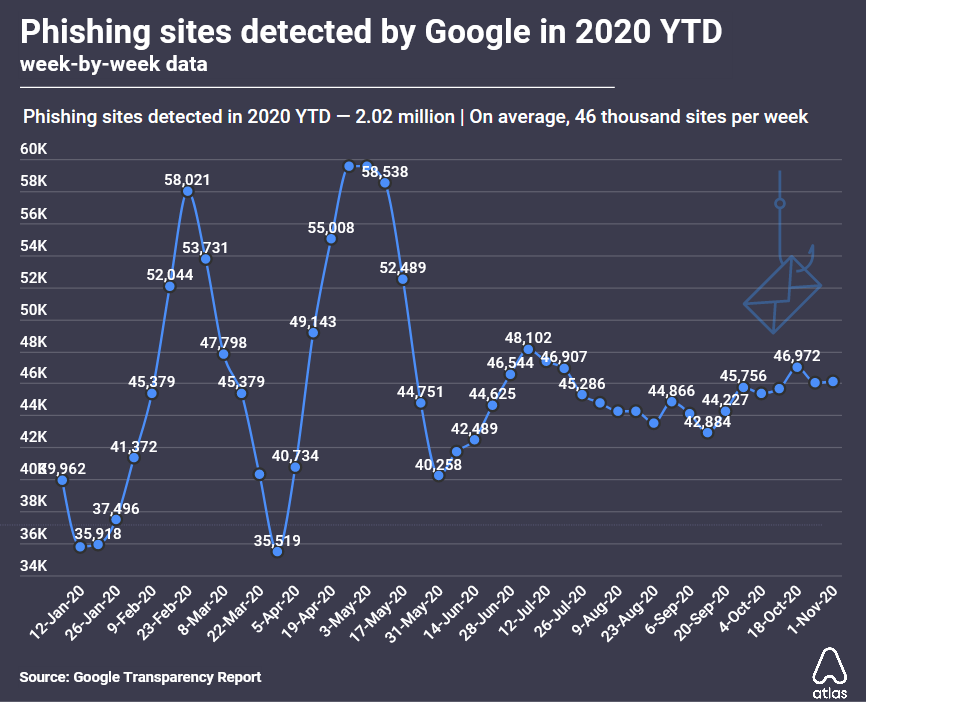
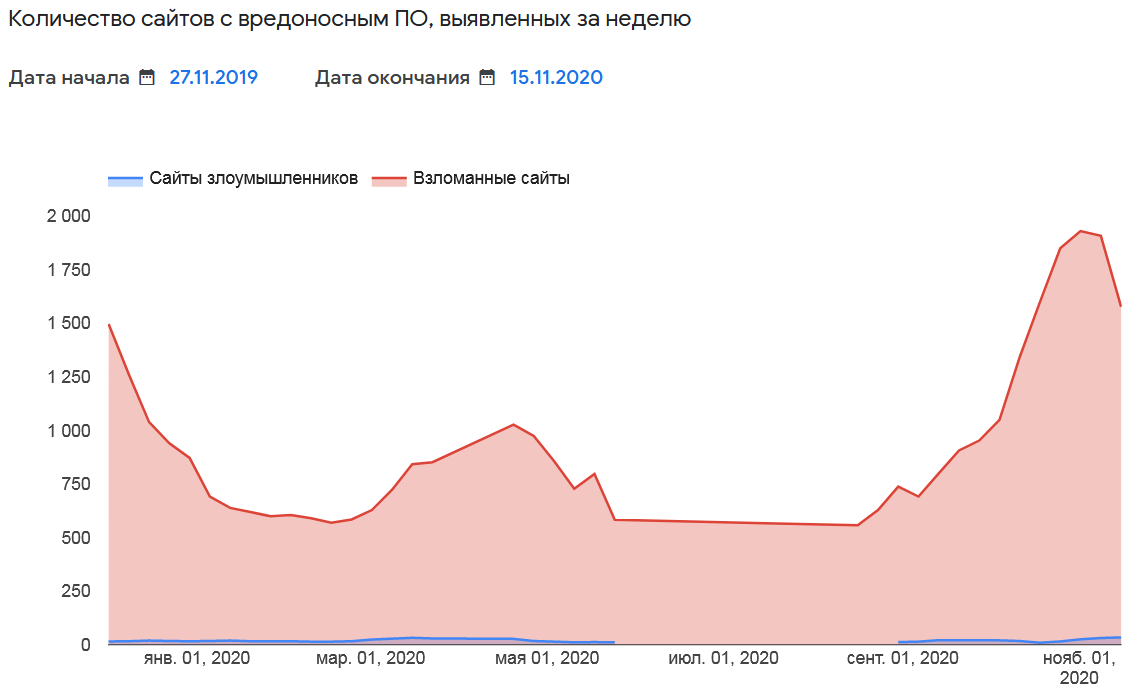
По данным исследования, сегодня основной целью злоумышленников становится не кража данных, а остановка бизнеса. В 76% расследованных инцидентов атаки были связаны с шифрованием или разрушением инфраструктуры. Более чем в 90% случаев конечной целью злоумышленников было получение выкупа.
Исследование также показывает, что современные атакующие все чаще используют штатные инструменты администрирования, такие как PowerShell, CMD и средства удаленного управления. Это позволяет маскировать вредоносную активность под обычную работу системных администраторов и дольше оставаться незамеченными.
Эксперты Jet CSIRT отмечают, что под угрозой находятся любые компании, вне зависимости от отрасли или масштаба. Наиболее часто расследованные инциденты пришлись на промышленность и производство (20%), ретейл и e-commerce (18%), государственный сектор (13%), ИТ и телеком (10%), а также финансовые организации (10%). Следует отметить, что и небольшие компании-подрядчики или партнеры также подвержены риску и часто становятся точкой входа для атак на более крупные организации.
Помимо статистики, исследование содержит описание наиболее распространенных тактик злоумышленников, практические рекомендации по повышению киберустойчивости и чек-лист наиболее типичных недостатков инфраструктуры, которые приводят к успешной компрометации. Полную версию исследования можно посмотреть по ссылке.
Реклама, 18+. АО «Инфосистемы Джет» ИНН 7729058675
ERID: 2Vfnxx6qEpT



