








Недавно организацию SANS Institute поразила фишинговая атака, в ходе которой киберпреступники смогли получить доступ к ящику электронной почты одного из сотрудников. Теперь SANS раскрыла детали атаки и выложила индикаторы компрометации (IoC).
На прошлой неделе стало известно, что группа киберпреступников смогла ввести в заблуждение служащего SANS, завладела его ящиком электронной почты и перенаправила себе 513 важных писем.
В результате злоумышленникам удалось завладеть в общей сложности 28 тыс. записей персональных данных, принадлежащих сотрудникам SANS.
Сама организация решила раскрыть все подробности взлома, чтобы максимально проинформировать сообщество исследователей в области кибербезопасности. Например, с помощью опубликованных IoC другие компаниями могут убедиться в том, что их не затронули операции киберпреступников.
По словам представителей SANS, атака началась с единственного фишингового письма, замаскированного под уведомление об общем доступе к файлу через SANS SharePoint. Сам файл якобы представлял собой таблицу под именем «Copy of July Bonus 24JUL2020.xls».
В письме также находилась кнопка «Open», которую адресату предлагали нажать, чтобы получить доступ к файлу.
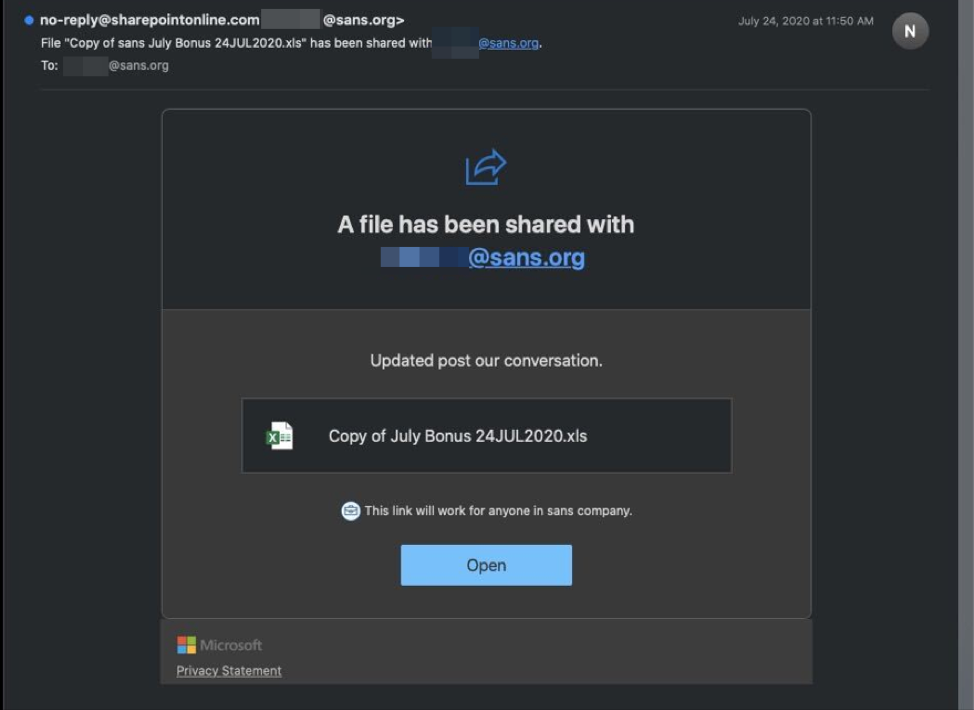
После клика по кнопке браузер открывал страницу https://officei6zq49rv2p5a4xbq8ge41f1enjjczo.s3.us-east-2.amazonaws [.]com/index.html, которая сразу же предлагала пользователю ввести учётные данные от аккаунта Office 365.
При этом на компьютер жертвы устанавливался OAuth-аддон Microsoft Office OAuth под именем «Enable4Excel». После установки вредоносное приложение начинало мониторить электронные письма, пытаясь найти в них определённые ключевые слова.
Если такие слова находились, само письмо тут же отправлялось на специальный адрес — daemon [@] daemongr5yenh53ci0w6cjbbh1gy1l61fxpd.com. Список ключевых слов выглядел так:
- agreement
- Bank
- bic
- capital call
- cash
- Contribution
- dividend
- fund
- iban
- Payment
- purchase
- shares
- swift
- transfer
- Wire
- wiring info
Полные индикаторы компрометацию можно найти на официальном сайте SANS. Эксперты утверждают, что киберпреступники атаковали и другие компании этой же схемой.






