







Новая вредоносная кампания идет полным ходом с начала ноября. В ходе этих атак киберпреступники заражают серверы Linux новым вымогателем JungleSec, используя в процессе незащищенный IPMI-интерфейс.
IPMI представляет собой интеллектуальный интерфейс управления платформой, предназначенный для автономного мониторинга и управления функциями, встроенными непосредственно в аппаратное и микропрограммное обеспечения серверных платформ.
Если этот интерфейс неправильно сконфигурирован, он может позволить атакующим получить удаленный доступ к системе, а также поспособствует получению полного контроля над ней за счет использования учетных данных по умолчанию.
«В процессе общения с двумя жертвами выяснилось, что злоумышленники установили вымогатель JungleSec через интерфейс IPMI на сервере. В одном случае в интерфейсе использовался установленный по умолчанию производителем пароль. Другая же жертва настроила IPMI правильно, однако преступники использовали имеющиеся уязвимости», — пишут эксперты на BleepingComputer.
После получения доступа злоумышленники перезагружают компьютер в однопользовательском режиме, чтобы получить root-доступ. Далее загружается программа для шифрования файлов.
После завершения процесса шифрования злоумышленники оставляют записку с требованиями выкупа (ENCRYPTED.md). В ней содержатся инструкции по оплате выкупа и расшифровке файлов:
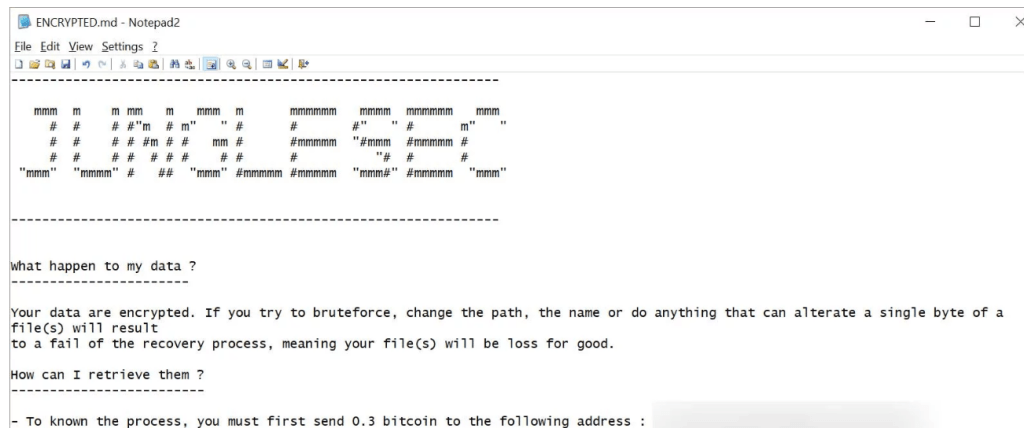
Злоумышленники используют домен junglesec@anonymousspeech[.]com для связи с жертвами. Сумма выкупа равняется 0,3 биткоина. Эксперты сообщают, что многие жертвы после оплаты не получили никакого ответа от вымогателей.






