Когда год назад группа под названием Shadow Brokers опубликовала целый набор украденных у АНБ инструментов для взлома, большинство исследователей сконцентрировали внимание на самых мощных из них, так называемых zero-day эксплойтах, которые служат для установки вредоносных программ. Но недавно группа венгерских исследователей безопасности из лаборатории CrySyS Lab обратилась к другим данным, раскрытым Shadow Brokers. Они изучили коллекцию скриптов и инструментов сканирования, которые АНБ использует для обнаружения хакерских группировок из других стран, и выяснили, что те позволяют американцам идентифицировать международных шпионов и киберпреступников задолго до того, как об их деятельности узнает мировое сообщество инфобезопасности.
Кажется, эти скрипты представляют не меньший интерес, чем всем известные эксплойты. Они показывают, что в 2013 году (когда, как считается, эксплойты и были украдены Shadow Brokers), АНБ отслеживала как минимум 45 национальных операций, известных в сообществе как Advanced Persistent Threats, или APT. Некоторые из них уже получили известность в сообществе, другие до сих пор оставались засекреченными.
Скрипты, которые исследовали венгры, были разработаны командой АНБ под названием Territorial Dispute, или TeDi. Как сообщает The Intercept со ссылкой на разведывательный источник, АНБ создали эту команду после того, как в 2007 году некие злоумышленники, предположительно из Китая, похитили чертежи военного самолета Joint Strike Fighter и некоторые другие конфиденциальные данные. Задачей команды было быстрое обнаружение киберпреступных группировок из других стран, а также информирование сотрудников АНБ в случае, если заражаемые ими компьютеры атакуются кем-то еще.
Все эти усилия нужны, чтобы помешать краже инструментов АНБ и гарантировать безопасность агентам американской разведки. Если иностранный киберразведчик по неосторожности себя выдаст, это также может спровоцировать обнаружение и американского агента. Кроме того, скрипты, разработанные TeDi, позволяют вычислять наиболее привлекательные для взлома компьютеры в тех географических зонах, о которых у АНБ недостаточно инсайдерской информации. Если компьютер уже привлек много взломщиков из других стран, это верный признак того, что он является целью и для американских агентов.
Для поиска киберпреступников Territorial Dispute используют цифровые подписи. Они работают как отпечатки пальцев и могут идентифицировать присутствие группы взлома через названия файлов, фрагменты кода известных вредоносных программ, неоднократно использованных участниками APT, определенные изменения в настройках операционной системы компьютера. Такие элементы называются индикаторами взлома (indicators of compromise, или IoC).
Поскольку ни одна из известных APT-групп не названа своим именем в скриптах (вместо этого АНБ называют их Sig1, Sig2 и т. д.), венгерские исследователи попытались узнать, какие известные группировки и вредоносные программы скрываются за этими условными обозначениями.
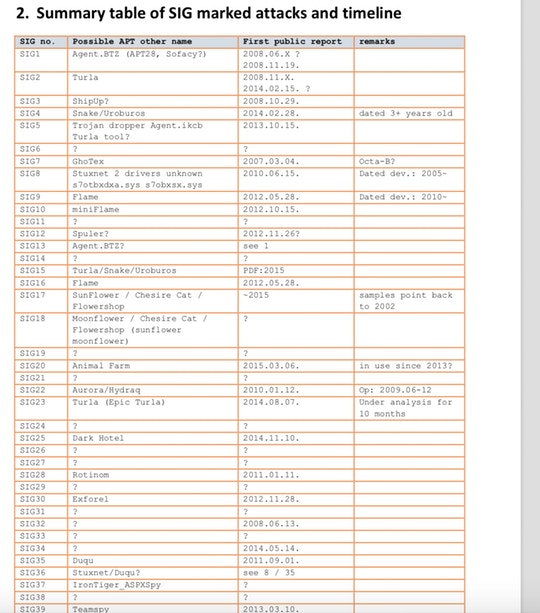
Например, они выяснили, что АНБ могли знать о деятельности группировки Dark Hotel (предположительно созданной в Южной Корее и атакующей компьютеры в Азии) еще в 2011 году, то есть за три года до того, как о ней стало известно сообществу безопасности. Sig.1 — обозначение, присвоенное червю Agent.btz, который скорее всего был внедрен в секретную военную компьютерную систему США агентом из России. Sig.16 может относиться к шпионскому набору Flame, созданному предположительно группировкой из Израиля.
Команда CrySyS Lab планирует рассказать о своих находках на предстоящем саммите Kaspersky Security в Канкуне и рассчитывает, что и другие специалисты присоединятся к их исследованиям. Сотрудники лаборатории также надеются, что эти данные помогут сообществу выяснить, какие группировки стоят за недавно открытыми вредоносными программами.