








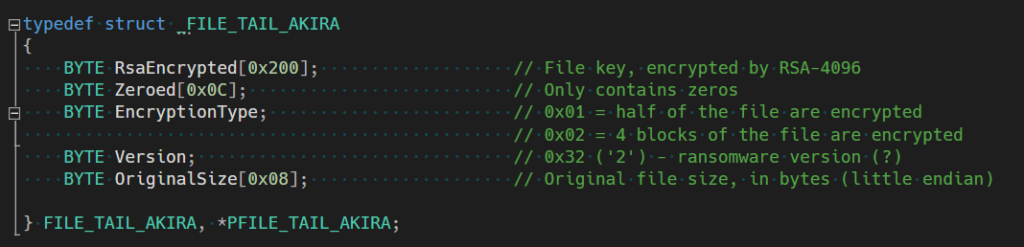







Эксперты D3Lab обнаружили поддельную страницу UniCredit, которая обещает пользователям $100 за установку приложения и ещё по $50 за каждого приглашённого друга. Щедрость, как обычно, заканчивается там, где начинается APK-файл.
Мошенники зарегистрировали домен unicredit-tme[.]shop и оформили его под банковскую акцию.
Кнопка загрузки вела не в официальный магазин, а в Telegram-бота. Тот уже уговаривал жертву установить приложение вручную и разрешить загрузку из неизвестных источников.
Скачанный APK маскируется под приложение UniCredit, но на деле является загрузчиком. Внутри него спрятан банковский троян Albiriox — вредонос не скачивается отдельно из интернета, а собирается прямо на устройстве из замаскированных файлов. Такой трюк снижает шанс, что защитные системы успеют перехватить загрузку.

После установки троян просит доступ к специальным возможностям Android, СМС, уведомлениям и отображению поверх других окон. Этого хватает, чтобы читать экран, нажимать кнопки, перехватывать коды подтверждения и показывать фальшивые формы входа.
Albiriox продаётся по модели «вредонос как услуга» примерно за $650 в месяц и, по данным исследователей, нацелен более чем на 400 банковских, финтех- и криптоприложений. Оператор получает удалённый доступ к телефону почти как через VNC и может подтверждать переводы прямо с устройства жертвы, обходя двухфакторную аутентификацию.



