















Если ваш iPhone в последнее время пытается раскалиться до температуры мартеновской печи и сходит с ума от бесконечной череды пушей, расслабьтесь, дело не в вас и даже не в бета-версии iOS. Telegram снова отличился: в приложении всплыл баг, который заставляет технику плавиться.
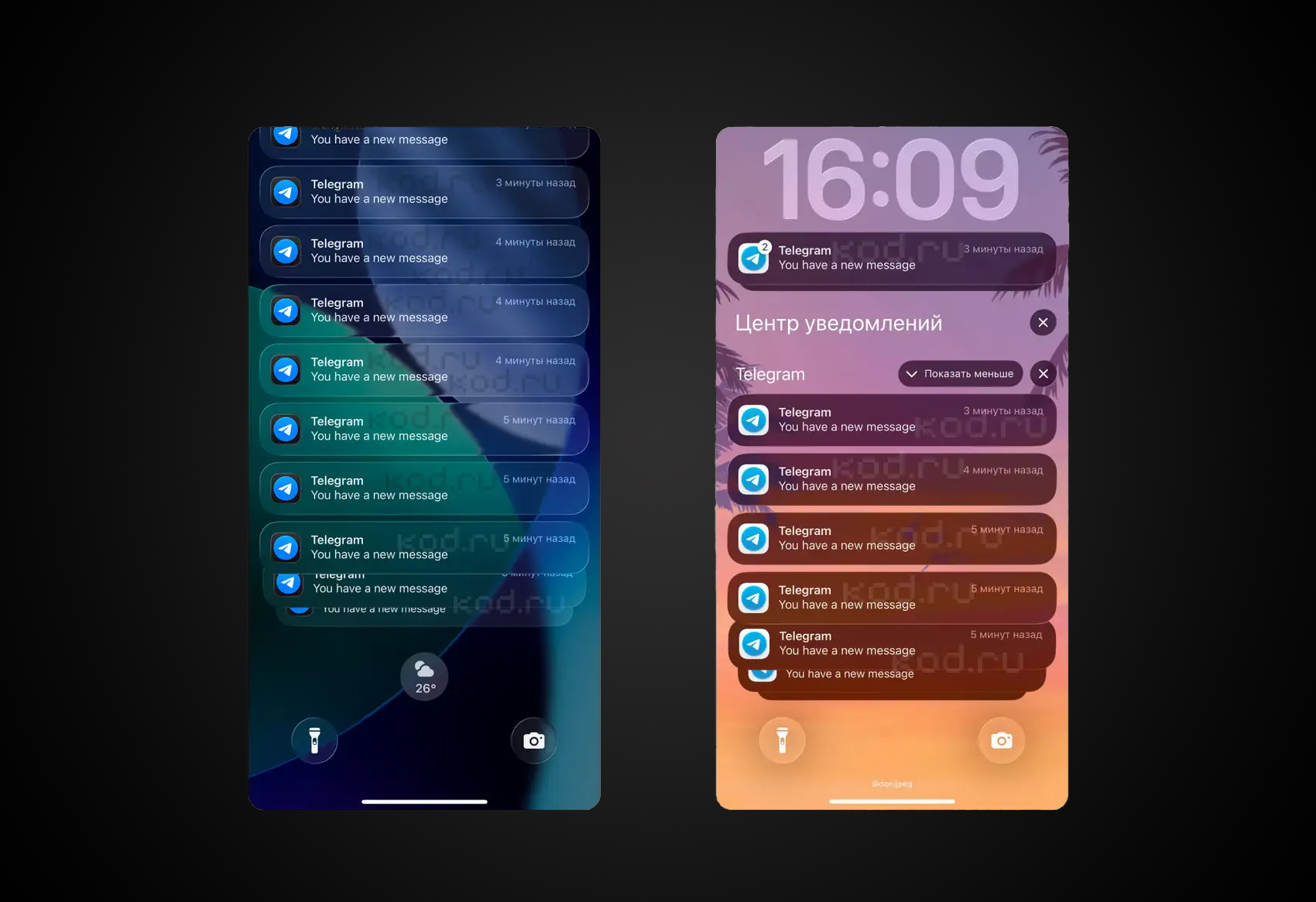
Мессенджер начинает в фоновом режиме штамповать сотни ложных уведомлений, сообщает «Код Дурова».
На экран пачками валится англоязычный текст "You have a new message", даже если у вас включен русский язык и отображение текста сообщений. Нажимать на них бесполезно — внутри ничего нет. Пуши прилетают буквально каждую минуту, превращая шторку уведомлений в хаос.
Но это ещё полбеды. Параллельно с этим адом iPhone или iPad начинает нехило греться и сжирать батарею прямо на глазах (у некоторых улетает по 11% за полчаса в полном idle).
Нагрев бывает настолько сильным, что Apple просто ставит зарядку на паузу, пока девайс не остынет. Один из пострадавших журналистов даже приспособил геймпад с кулером, чтобы хоть как-то зарядить смартфон.
Жалобы поползли ещё в мае, но после обновления Telegram до версии 12.9 баг накрыл пользователей с новой силой. Судя по всему, кривой код мессенджера закольцовывает фоновые процессы, заставляя процессор пахать на износ.
Как с этим жить? Панацеи пока нет — разработчики молчат, а регулярные патчи проблему до конца не вычистили. Единственное временное спасение — полная переустановка приложения:
- Зайдите в Telegram: Настройки → Данные и память → Использование памяти и почистите кеш.
- Убедитесь, что помните пароли и сможете войти обратно (проверьте доступ к почте или другим устройствам для кода).
- Снесите Telegram с устройства.
- Скачайте его заново из App Store и аутентифицируйтесь.
Спойлер: это помогает, но не всем и не навсегда. У кого-то сбой возвращается через неделю-две. Так что запасаемся терпением, ждём нормальный фикс от команды Дурова и держим огнетушитель под рукой.



