













Внезапные перезагрузки Windows во время важной работы давно стали интернет-мемом, причём настолько, что добрались даже до сериалов Netflix. И вот Microsoft решила в очередной раз отреагировать на эту боль пользователей. Правда, не за счёт радикальных изменений в системе обновлений, а куда более скромным способом: напомнив, как настроить период активности в Windows.
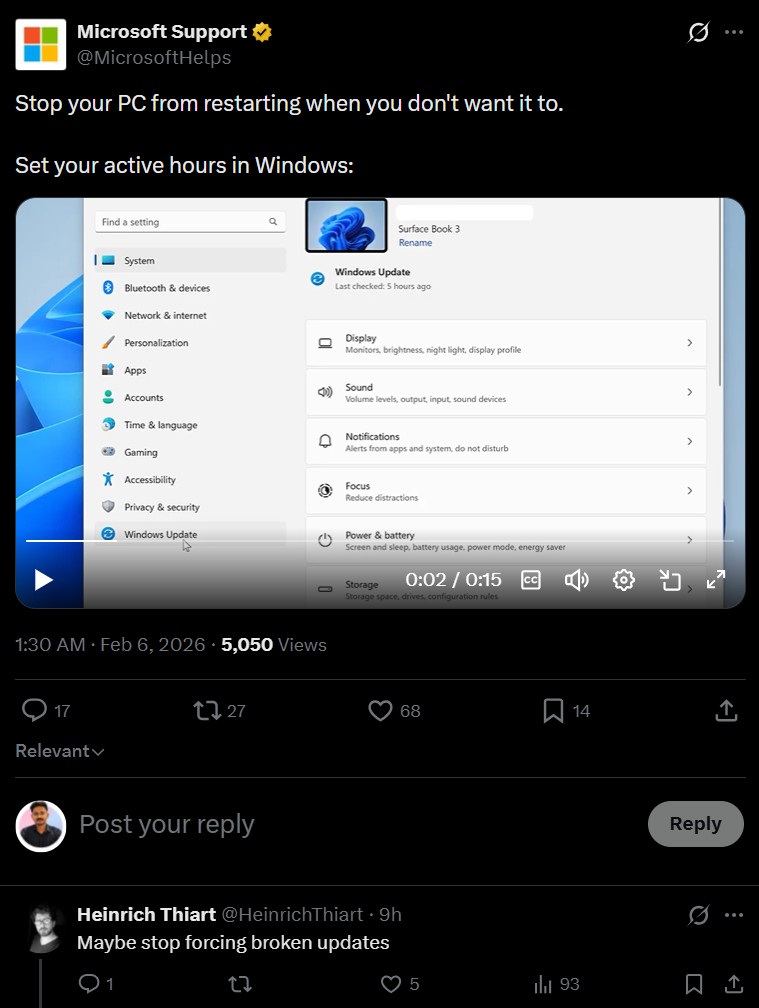
На днях поддержка Microsoft опубликовала в X (бывший Twitter) 15-секундное видео с инструкцией о том, как запретить системе перезагружаться в рабочее время.
Сам ролик оказался вполне безобидным, но формулировка в начале поста вызвала шквал иронии и критики.
«Запретите компьютеру перезагружаться, когда вам это не надо», — написали в Microsoft.
На это самый популярный комментарий быстро ответил:
«Может, для начала перестанете навязывать сломанные обновления?»
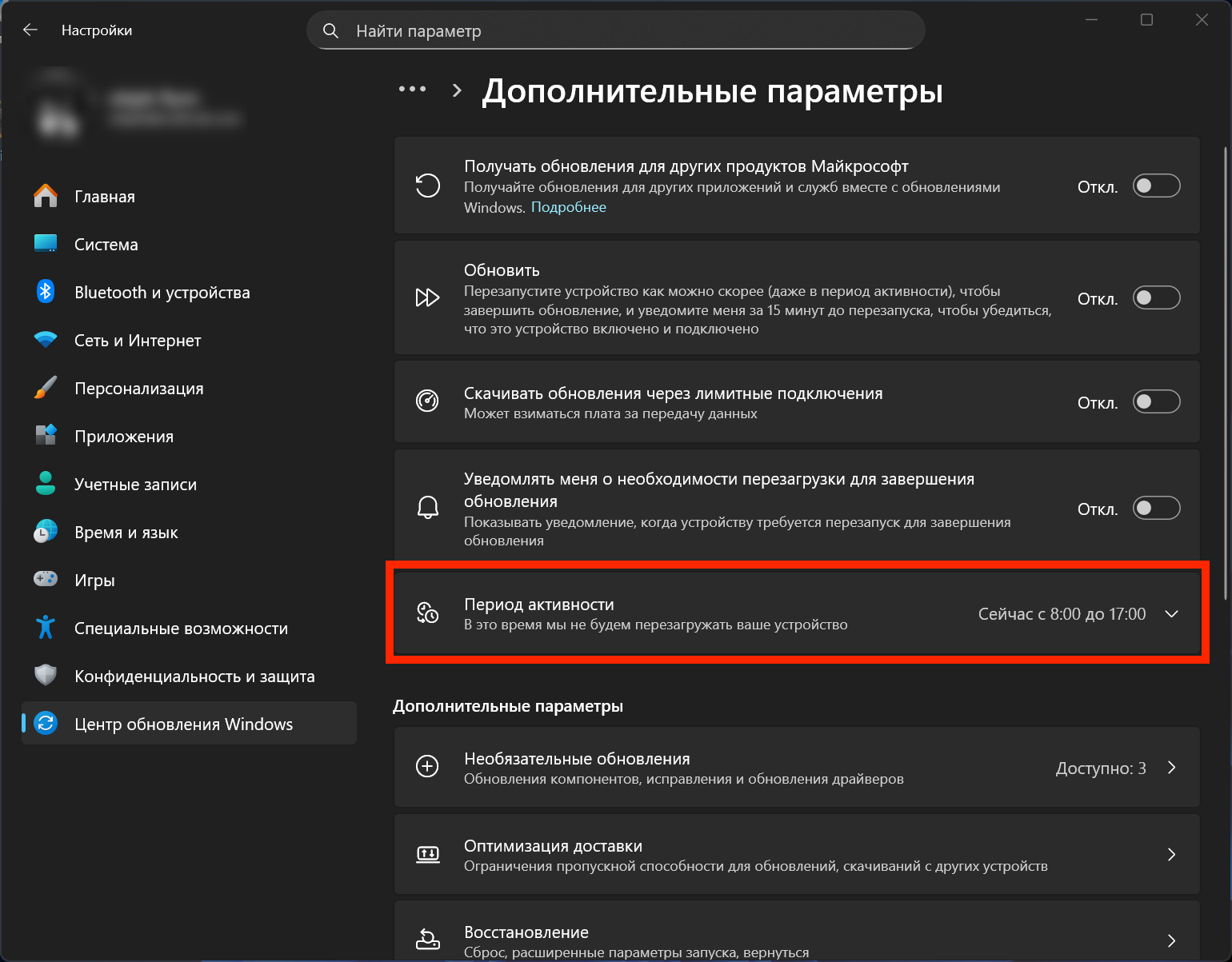
Функция «Период активности» при этом далеко не нова, ей почти десять лет. Впервые она появилась ещё в Windows 10. Суть проста: пользователь задаёт временной интервал, в который система не будет автоматически перезагружаться для установки обновлений.
Изначально диапазон был ограничен 12 часами, позже его расширили до 18. В Windows 11 Microsoft пошла дальше и включила автоматическую настройку этого периода на основе поведения пользователя — именно этот режим сейчас включён по умолчанию.
Проблема в том, что далеко не у всех есть стабильный график работы. Если вы иногда работаете ночью или в нестандартное время, «умный» алгоритм легко может промахнуться. Формально это всё ещё может привести к перезагрузке в неподходящий момент, хотя Windows обычно заранее показывает множество уведомлений. Но при аудитории в сотни миллионов пользователей неудивительно, что у кого-то такие ситуации всё же происходят.
В видео Microsoft показывает, как переключить активные часы с автоматического режима на ручной: нужно зайти в настройки Windows Update, выбрать дополнительные параметры и задать время вручную. В этом интервале система не будет перезагружаться сама.
Обсуждение под постом быстро ушло в привычное русло: пользователи снова обвиняют Microsoft в навязывании проблемных обновлений, требуют кнопку полного отключения апдейтов и критикуют компанию за агрессивное продвижение ИИ. В ход пошло и вирусное прозвище «Microslop», хотя сам пост вообще не касался искусственного интеллекта.
На фоне всей этой реакции Microsoft уже пообещала заняться «оздоровлением» Windows и до 2026 года сосредоточиться на стабильности, производительности и снижении навязчивости ИИ-функций. А пока корпорация предлагает пользователям хотя бы вручную настроить активные часы — чтобы очередное обновление не застало врасплох в самый неподходящий момент.



