













Google наконец запустила резервное копирование документов с Android-смартфонов в облако. Функция, которую компания готовила почти год, распространяется в стабильной версии Google Play Services 26.26.
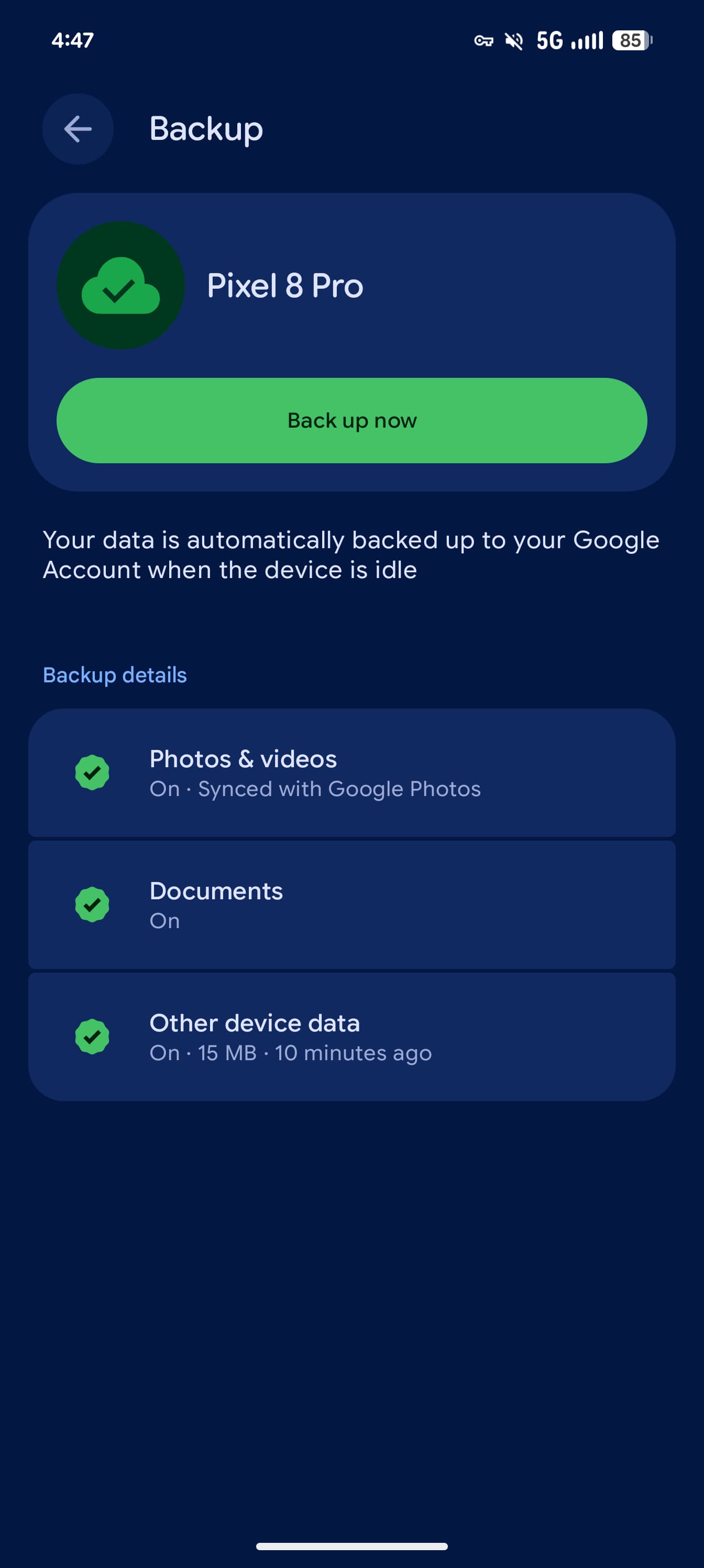
На смартфонах Pixel новый пункт «Документы» появляется в разделе «Настройки» → «Аккаунты и резервное копирование» → «Резервное копирование Google».
По умолчанию функция выключена, Google всё-таки не стала без спроса кормить Drive содержимым папки Downloads.
После активации документы автоматически загружаются в новую папку Android backups на Google Drive. Внутри создаётся отдельный каталог с названием смартфона. Поддерживаются PDF, DOC, PPT, XLS, ZIP и другие форматы. Под горячую руку попадают даже APK-файлы из папки загрузок.
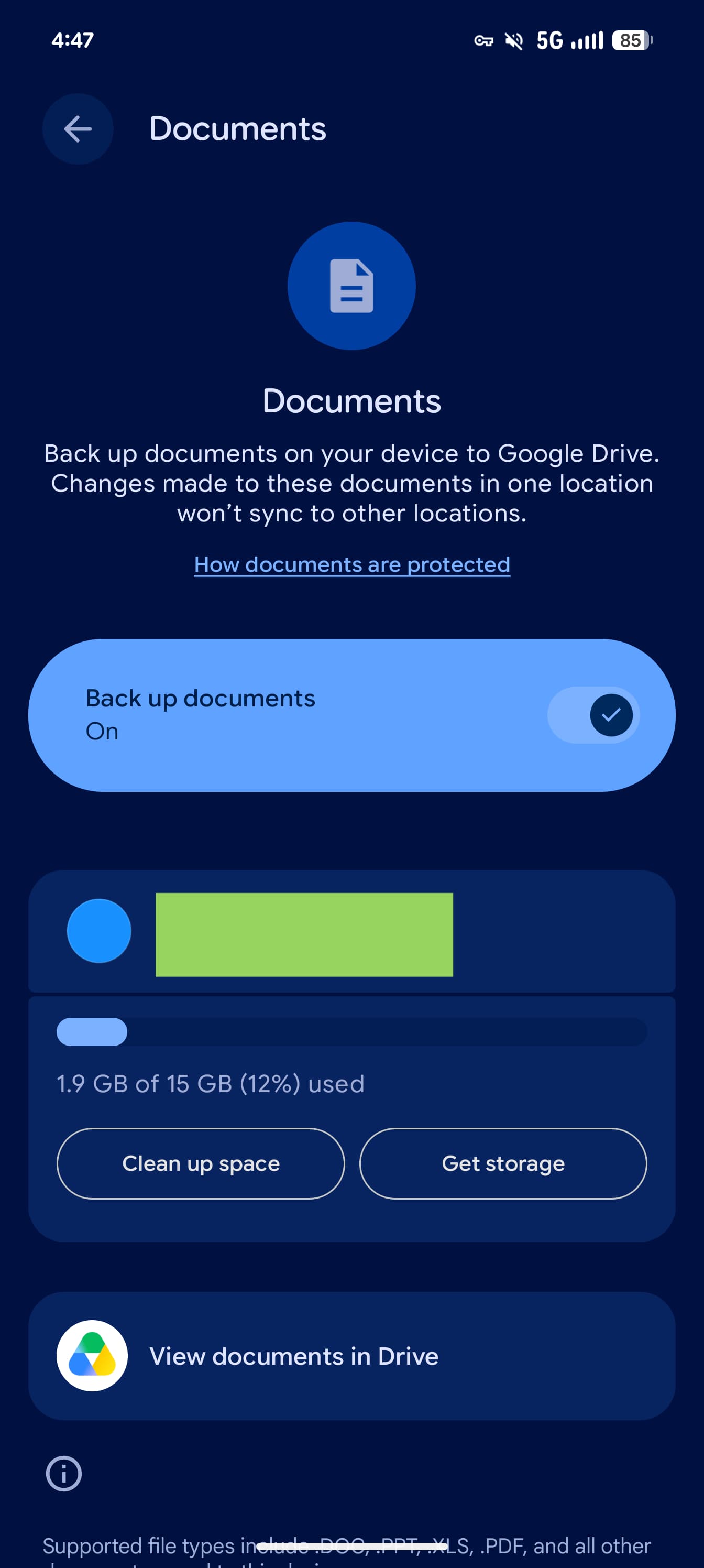
За облачный комфорт придётся расплачиваться гигабайтами: копии занимают место в хранилище Google Drive. На странице настройки можно проверить остаток, освободить пространство или, разумеется, купить дополнительное.
Есть и важный нюанс. Отключение резервного копирования не удаляет уже загруженные файлы, поэтому чистить папку на Drive придётся вручную. Полноценной синхронизации тоже нет: если изменить документ на смартфоне, его облачная копия автоматически не обновится, и наоборот.
Первые следы функции обнаружили ещё в августе 2025 года, а в феврале 2026-го Google официально упомянула её в обновлении Play System. Затем копирование документов появилось в бета-версии Play Services, и только теперь добралось до стабильной сборки.



