













Разработчики WhatsApp (принадлежит признанной экстремистской организацией корпорации Meta, запрещенной в России) решили сэкономить пользователям ещё несколько лишних нажатий. В тестовой версии мессенджера для Android обнаружили новый виджет, который позволит записывать и отправлять голосовые сообщения прямо с домашнего экрана смартфона.
О находке сообщил ресурс WABetaInfo, изучивший бета-версию WhatsApp для Android 2.26.24.2. Пока функция находится в разработке и даже тестерам ещё недоступна, но направление вполне понятно.
Судя по опубликованным данным, виджет получит компактный размер 3×1 и будет выглядеть максимально просто: надпись «Tap to record» и кнопка с микрофоном.
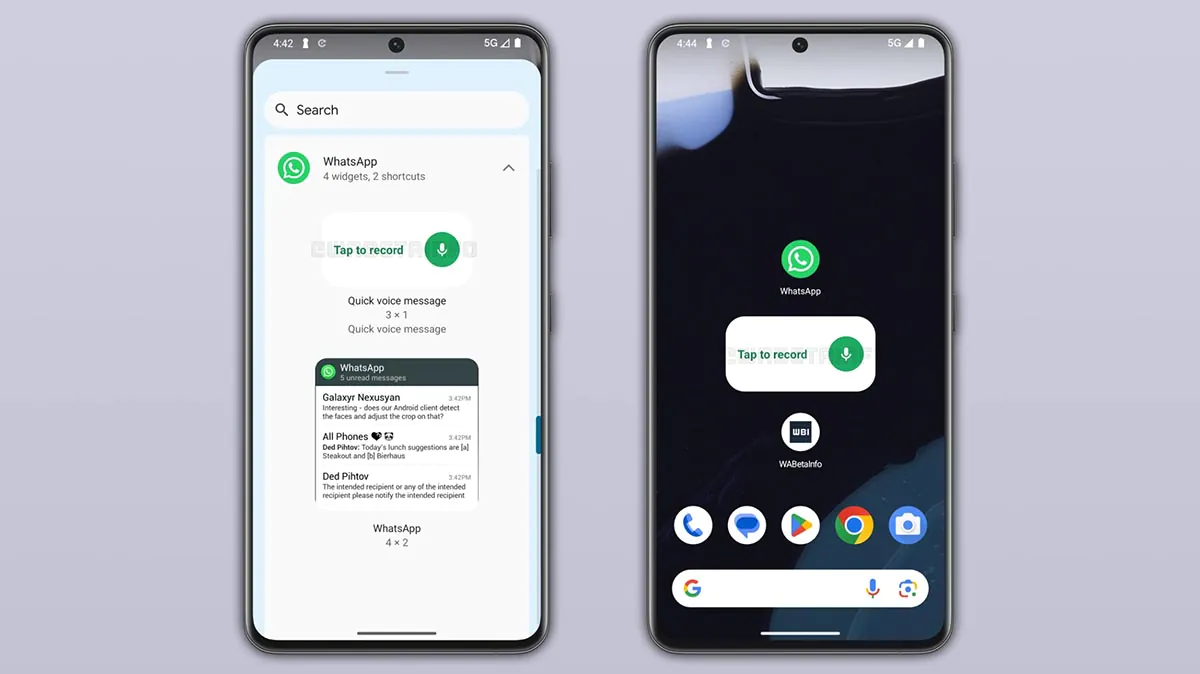
После завершения записи WhatsApp предложит выбрать получателя. Причём речь идёт не только об одном контакте или чате. Сообщается, что голосовое сообщение можно будет отправить сразу нескольким людям одновременно.
Сейчас для такого сценария приходится сначала записывать голосовое сообщение, затем пересылать его нужным контактам по очереди. Новый виджет убирает лишние действия и превращает процесс практически в аналог голосовой рассылки.
Пока новинка спрятана в тестовых сборках и официально не анонсирована. Но обычно такие находки появляются за несколько недель или месяцев до выхода функции в публичную бета-версию, а затем и в стабильный релиз.
Если идея доберётся до финального релиза без изменений, любители голосовых сообщений получат ещё один повод реже печатать текст и чаще разговаривать со смартфоном.



