








Злоумышленники придумали очередной способ выманить логины и пароли — на этот раз через вложения в формате SVG. В почтовых рассылках пользователям и компаниям начали приходить такие файлы с заманчивыми названиями, и при открытии они ведут на фишинговые сайты, маскирующиеся под Google или Microsoft.
Атака выглядит так:
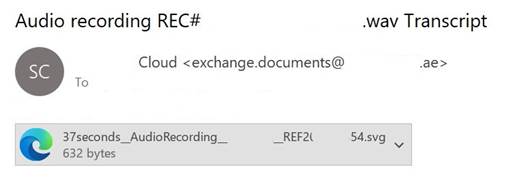
- Приходит письмо с вложением
.svg— якобы аудиофайл или документ. - Вы открываете его в браузере — и видите кнопку «Прослушать» или «Подписать документ».
- Жмёте — и попадаете на фейковую страницу входа, похожую на форму аутентификации Google или Microsoft.
- Вводите логин и пароль — и передаёте их прямиком в руки мошенников.
SVG-файлы — это векторные изображения, но в отличие от .jpg или .png они могут содержать JavaScript и HTML. Именно за счёт этого SVG превращается из картинки в маленький вредонос, способный перенаправлять на фишинговые ресурсы или прямо в себе содержать соответствующий код.
Что происходит сейчас, по данным «Лаборатории Касперского»:
- В марте 2025 года количество подобных атак выросло почти в 6 раз по сравнению с февралем.
- С начала года по миру уже зафиксировано больше 4 тысяч таких писем.
- Основная цель — украсть доступ к аккаунтам, особенно корпоративным.
Атаки пока достаточно просты технически: файл либо сразу открывает поддельную страницу, либо перенаправляет на неё. Но специалисты предупреждают: подход может быть легко усложнён и использован в целевых атаках, особенно против компаний.






