







Компания Google анонсировала выпуск OSV-Scanner — бесплатного инструмента автоматизированного поиска уязвимостей, релевантных для конкретного проекта. Новинка позволяет выявить все зависимости, сопоставить список с информацией об известных проблемах, занесенной в базу данных OSV, и определить необходимость патчинга или обновления.
Написанный на Go сканер предоставляет пользовательский интерфейс для доступа к OSV (сводной базе уязвимостей в opensource-проектах, пополняемой Google) и совместим с Linux, macOS и Windows. Для создания списка зависимостей достаточно задать просмотр каталога проекта; можно также вручную вводить путь ко всем файлам манифеста.
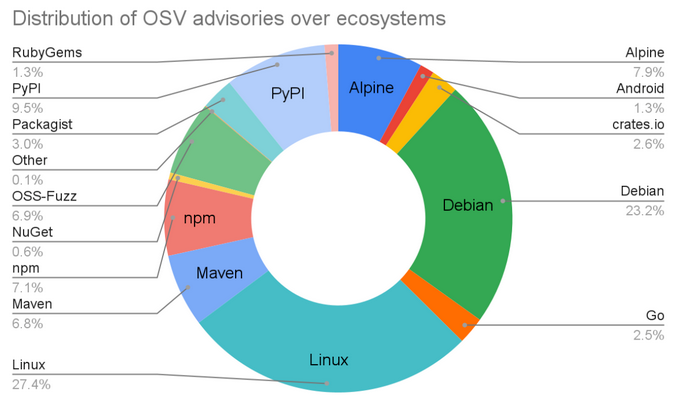
Запущенная в прошлом году база уязвимостей OSV изначально включала скромный набор данных, собранных в рамках проекта OSS-Fuzz. В настоящее время платформа OSV.dev поддерживает 16 экосистем, в том числе популярные языки программирования, Linux-дистрибутивы (Debian и Alpine), Android и Linux Kernel.
Количество бюллетеней по безопасности, осевших в репозитории, превысило 38 тысяч (год назад в OSV числилось 15 тыс. записей). Половина зафиксированных уязвимостей приходится на долю Linux и Debian.
Сайт OSV.dev был полностью перестроен и теперь может похвастаться более удобным UI и расширенной информацией по каждой уязвимости. В дальнейшем Google планирует улучшить поддержку экосистемы C/C++ (сейчас она бедно представлена) и доработать OSV-Scanner, превратив его в полноценный инструмент управления уязвимостями.






