







Специалисты по кибербезопасности выявили новую вредоносную кампанию, которую назвали “GO#WEBBFUSCATOR”. Злоумышленники рассылают фишинговые сообщения с вложенными злонамеренными документами. Картинка-приманка использует снимок с космического телескопа «Джеймс Уэбб».
Сам вредонос, распространяемый в этой кампании, написан на Golang. Напомним, что этот язык все чаще используется злоумышленниками, которые любят его за кросс-платформенность (позволяет писать под Windows, Linux, macOS) и устойчивость к обратному инжинирингу и анализу.
В свежей кампании, привлекшей внимание специалистов Securonix, атакующие копируют в систему пейлоад, который пока не детектируется антивирусными движками на VirusTotal.
Все начинается с фишингового письма с вложенным документом “Geos-Rates.docx”. Именно он загружает файл шаблона, содержащий обфусцированный VBS-макрос. Если у пользователя включена эта функциональность в Office, вредоносный код скачивает изображение в формате JPG — “OxB36F8GEEC634.jpg” с удаленного сервера xmlschemeformat[.]com.
На следующем этапе изображение декодируется в исполняемый файл msdllupdate.exe с помощью certutil.exe, который следом запускается. Кстати, JPG при открытии демонстрирует пользователю скопление галактик SMACS J0723.3-7327, опубликованное НАСА в июле 2022 года.
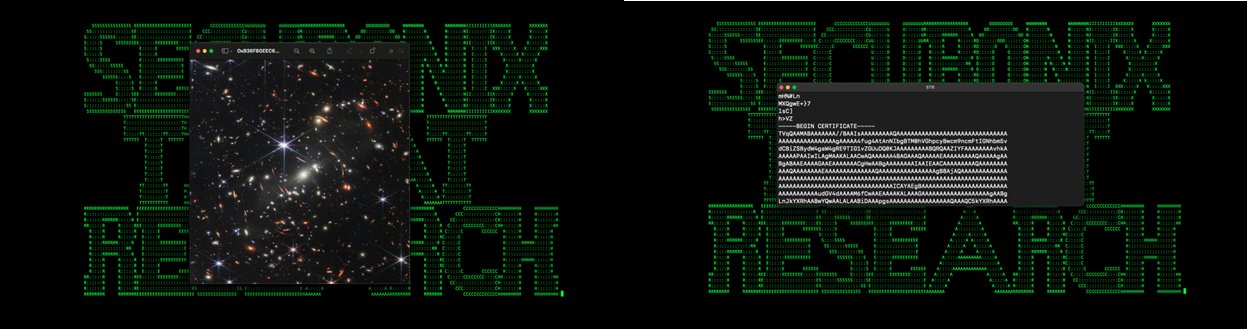
Но помимо изображения, файл несет дополнительный контент, замаскированный под сопутствующий сертификат. На деле это зашифрованный Base64 пейлоад, который превращается в 64-битный исполняемый файл. Для закрепления в системе вредонос копирует себя в директорию “%%localappdata%%\microsoft\vault\” и добавляет новый ключ в реестре.
В отчете Securonix специалисты приводят индикаторы компрометации (IoC).






