








Google ошибочно отправила внутренний билд в качестве обновления пользователям смартфонов Pixel. Этот билд предназначался для внутреннего использования сотрудниками Google, в распоряжение обычных пользователей он не должен был попасть.
На самом деле, внутренний билд представлял собой предстоящее обновление, которое должно прийти пользователям Pixel в июле. До выхода в паблик сотрудники Google тестируют эти версии на собственном оборудовании.
Такой подход позволяет выявить большинство багов до релиза обновления.
Один из пользователей Pixel заявил, что ему пришло обновление безопасности July 2019 OTA. У юзера был смартфон Pixel 3a XL.
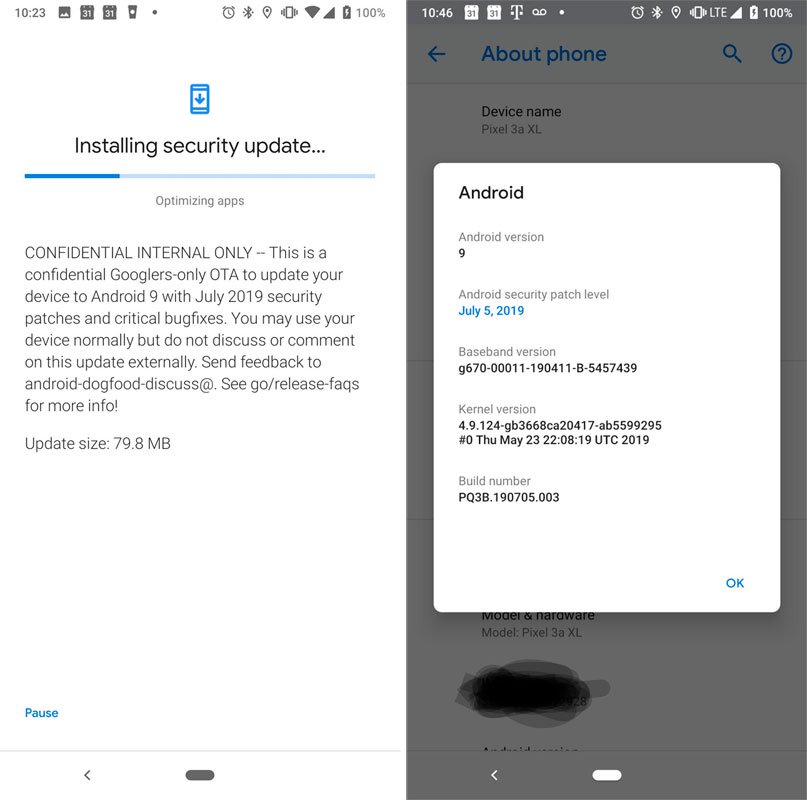
После установки номер сборки изменился на PQ3B.190705.003. От Google в настоящее время не поступало никаких комментариев относительно этого инцидента.






