







Пользователи игровой консоли PlayStation 4 пожаловались на новый баг, благодаря которому злонамеренное личное сообщение может вывести устройство из строя. Единственное, что сможет вернуть консоль к жизни — сброс к заводским настройкам.
Об одном эпизоде использования подобного вредоносного сообщения сообщил участник форума Reddit.
«Оказывается, существует баг, который выведет из строя вашу консоль и заставит сбросить ее к заводским настройкам. Проблему не решает даже удаление проблемного сообщения из мобильного приложения», — пишет пострадавший геймер.
«Это случилось со мной во время игры в Rainbow Six: Siege. Злонамеренное сообщение послал игрок другой команды, в итоге вся моя команда оказалась вне игры. Нам всем пришлось возвращать устройства к заводским настройкам».
«Только одному игроку удалось избежать этого, так как его личные сообщения были закрыты».
Следовательно, чтобы избежать неприятных последствий использования этого бага недобросовестными пользователями, рекомендуется закрыть свои личные сообщения. Пострадавший поделился скриншотом злонамеренного сообщения:
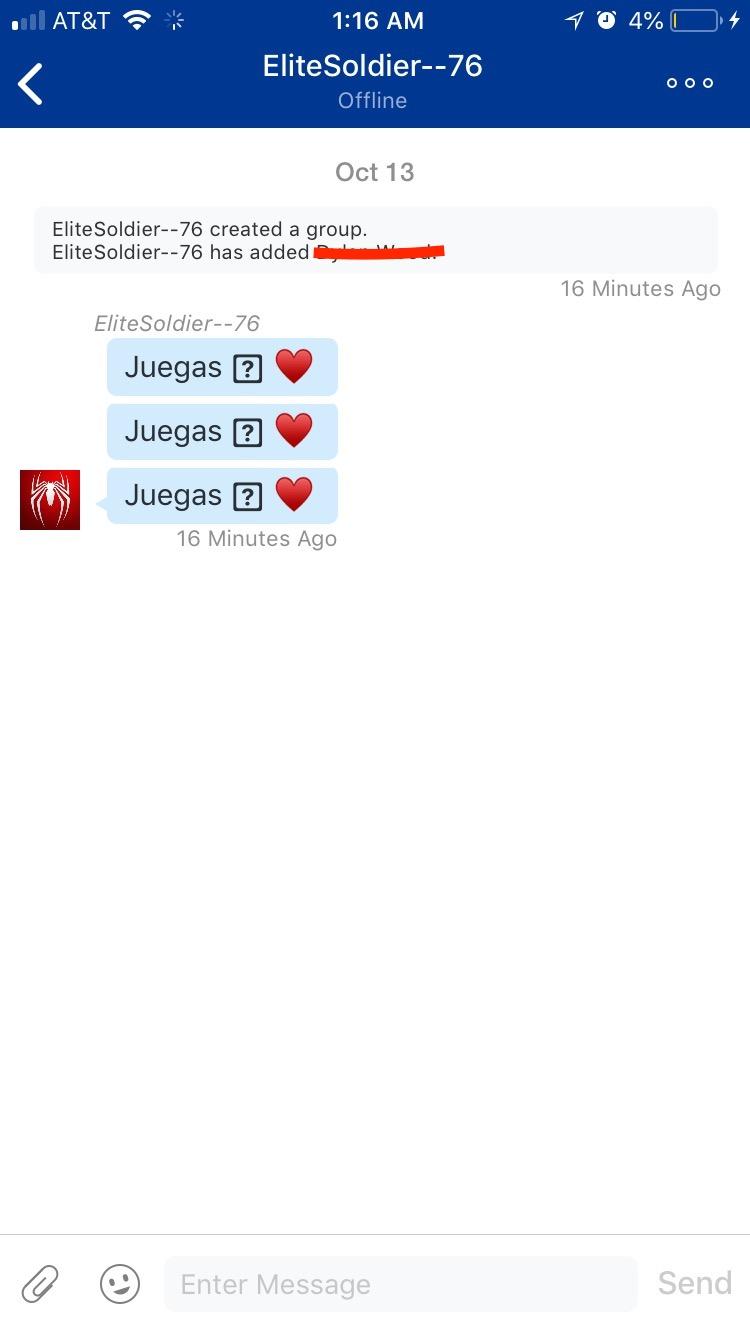
Если информация подтвердится, Sony должна будет выпустить обновление прошивки, в котором этот баг будет устранен.
В мае был опубликован эксплойт для прошивки 5.05 на PlayStation 4.






