















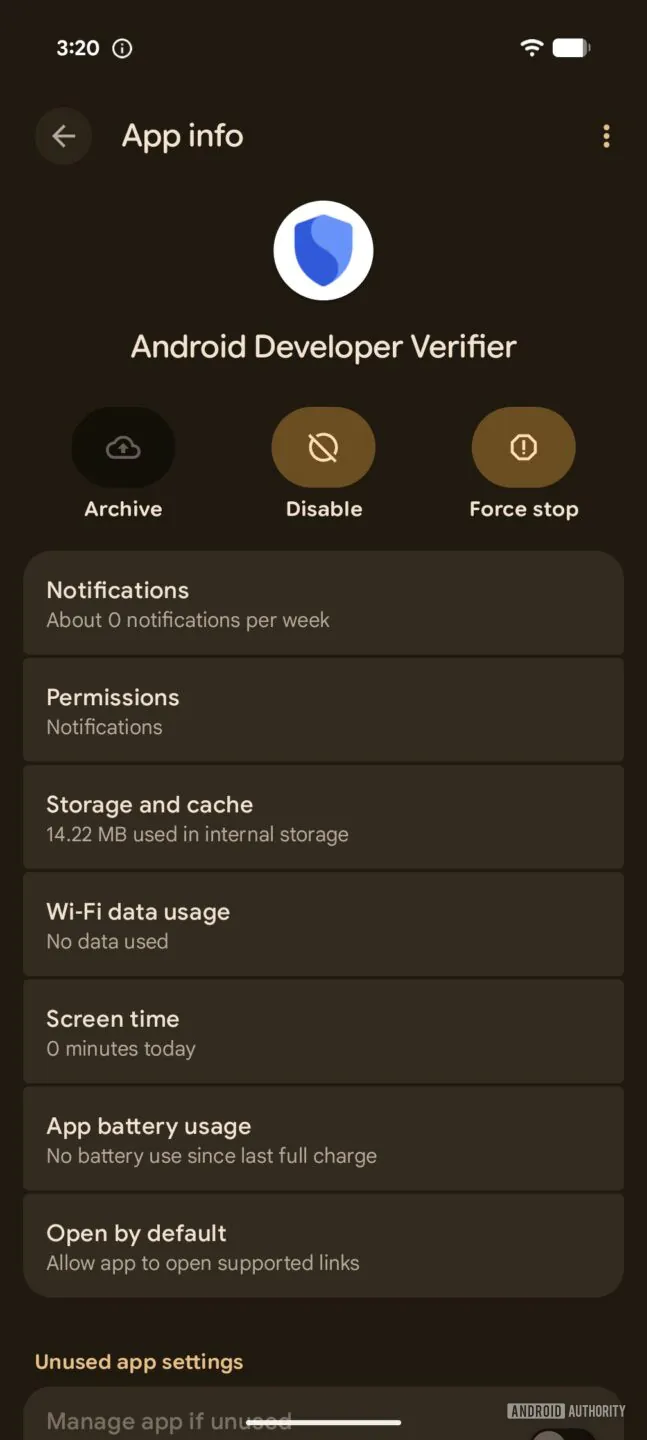
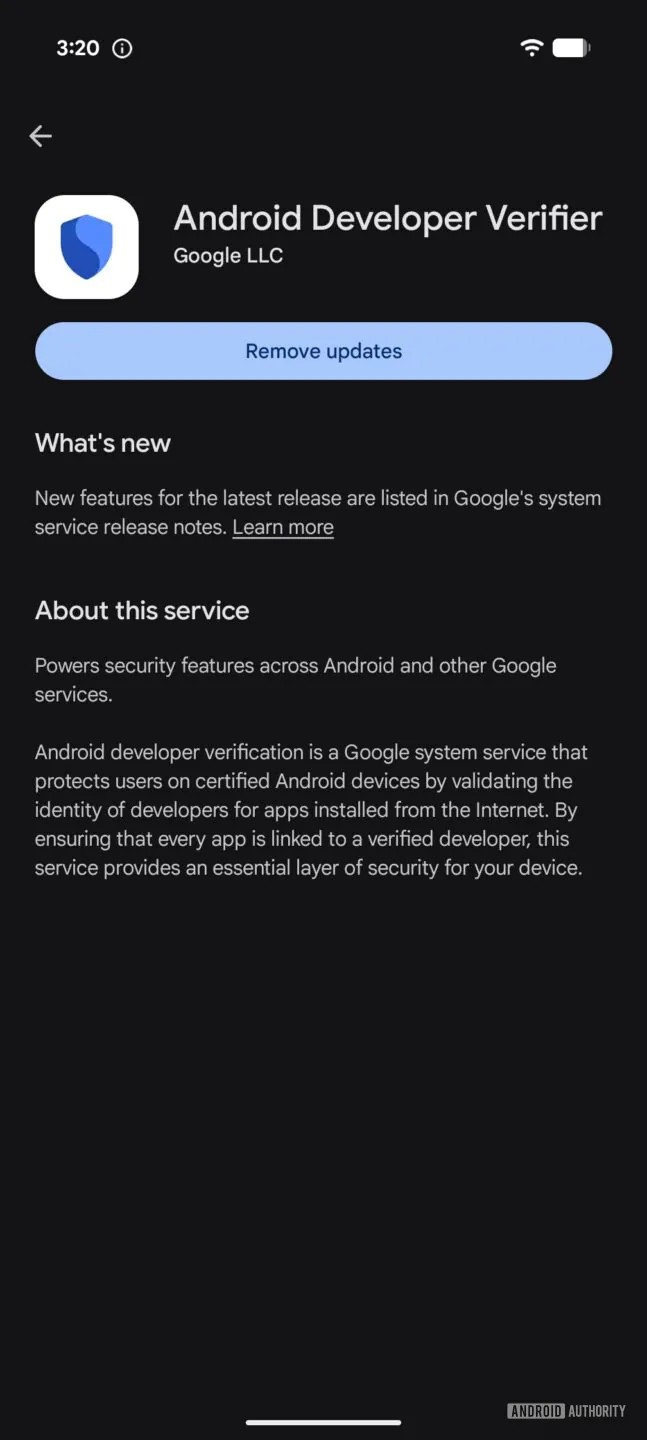
Пользователи Android начали замечать на смартфонах новое приложение Android Developer Verifier с идентификатором com.google.android.verifier. Оно появляется без отдельного запроса и готовит устройства к будущим ограничениям на установку APK из сторонних источников.
Сервис будет проверять, зарегистрировано ли устанавливаемое приложение за подтверждённым разработчиком.
Для получения такого статуса автору потребуется пройти проверку личности и предоставить Google юридические данные. Это не гарантирует безопасность программы, зато позволяет связать её с конкретным человеком или компанией.
Google объясняет ограничения борьбой с мошенниками. Те нередко звонят жертвам, пугают уголовным делом или бедой с родственником, а затем торопят отключить защиту и установить вредоносный APK. Обычные предупреждения пользователи в панике пролистывают, поэтому Android добавит полосу препятствий.
Для установки приложения неподтверждённого разработчика придётся включить режим разработчика, подтвердить отсутствие давления, перезагрузить смартфон, подождать 24 часа и повторно войти по ПИН-коду или биометрии. За сутки срочный сотрудник банка обычно успеет потерять интерес.
Android Developer Verifier распространяется через системные обновления Google, отказаться от его загрузки нельзя. Сейчас приложение у большинства пользователей бездействует. Новые требования начнут вводить 30 сентября в Бразилии, Индонезии, Сингапуре и Таиланде, а глобальное расширение запланировано на 2027 год и позднее.
Удалить сервис пока можно, но неизвестно, не вернётся ли он с очередным обновлением и поможет ли это обойти проверку.
Для опытных пользователей оставили лазейку: установка через ADB не подпадает под ограничения и не требует суточного ожидания. Пользовательские прошивки без сервисов Google тоже могут отказаться от новой системы.



