







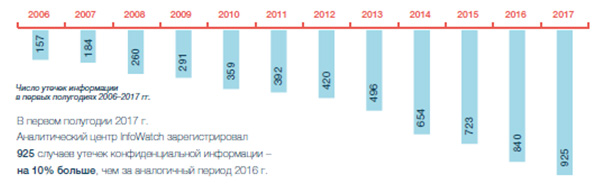
По данным Аналитического центра InfoWatch в первом полугодии 2017 года в мире было обнародовано в СМИ и иных открытых источниках 925 случаев утечки конфиденциальной информации, что на 10% превышает число утечек данных за аналогичный период 2016 года.
Объем скомпрометированных в результате утечек в январе-июне 2017 года записей персональных (ПДн) и платежных данных, включая номера социального страхования, реквизиты пластиковых карт и иную критически важную информацию, увеличился по сравнению с первым полугодием 2016 года почти в восемь раз — с 1,06 млрд до 7,78 млрд записей. Напомним, что общий объем скомпрометированной в 2016 году информации в мире составлял всего около трех миллиардов записей.
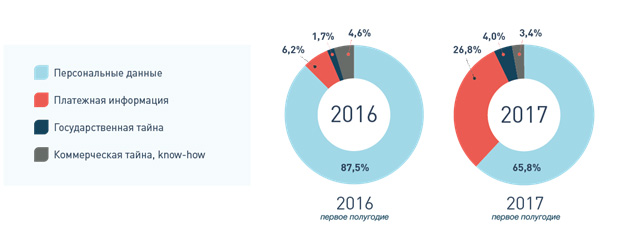
Резкое увеличение объема потерянной чувствительной информации в первом полугодии 2017 года произошло в результате 20 мега-утечек (от 10 млн записей), на которые пришлось 98% пострадавших записей ПДн и финансовых данных. По сравнению с аналогичным периодом прошлого года в распределении утечек по типам данных на 20% увеличилась доля платежной информации и симметрично сократилась доля ПДн.
Причиной 58% утечек в мире стали внутренние нарушители в организации. Существенно возросло среднее число пострадавших записей: в расчете на одну утечку в результате внешнего воздействия приходилось 13,6 млн записей (по сравнению с 2,4 млн в 2016 году) и 4,5 млн записей — на каждую утечку, допущенную по вине внутреннего нарушителя (0,8 млн в 2016 году).
«С начала 2017 года мы фиксируем в мире многократный рост объема скомпрометированных данных, увеличение “мощности” утечек, от которых страдает все больше чувствительной информации, — сказал аналитик ГК InfoWatch Сергей Хайрук. — С развитием цифровой экономики вопросы информационной безопасности переросли отраслевые рамки, и широко обсуждаются на самом высоком уровне. Сама тема утечек информации становится все более прозрачной и это должно позитивно сказаться на общем уровне культуры информационной безопасности. Даже в России пострадавшие организации начинают рассчитывать ущерб, который был нанесен им в результате той или иной утечки. Чтобы минимизировать эти риски, необходим комплексный подход к информационной безопасности предприятий, включая средства защиты от внешних и внутренних угроз».
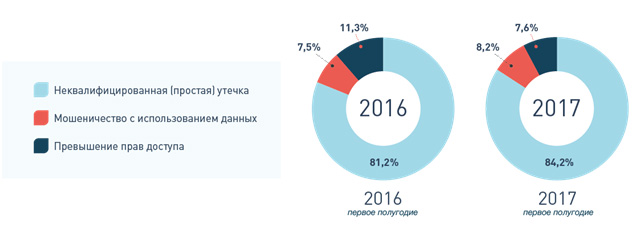
Доля утечек данных с неправомерным доступом к информации, включая злоупотребление правами доступа и внутренний шпионаж, составила менее 8% от общего числа случаев. Неквалифицированные утечки, которые не сопряжены с превышением прав доступа и использованием данных в целях мошенничества, были зафиксированы в 84% случаев.
В первом полугодии 2017 года по сравнению с аналогичным периодом 2016 года увеличилась доля утечек через сетевой канал и электронную почту. Снизились доли утечек данных в результате кражи/потери оборудования, с использованием съемных носителей и бумажных документов.
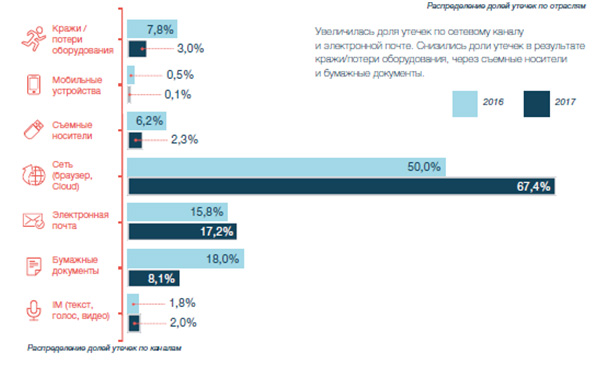
Большая часть утечек наиболее «ликвидной» платежной информации пришлась на два канала — в 45% случаев финансовые данные передавались в сеть Интернет через браузер или облачное хранилище, ещё 44% таких утечек произошли с использованием корпоративной электронной почты.
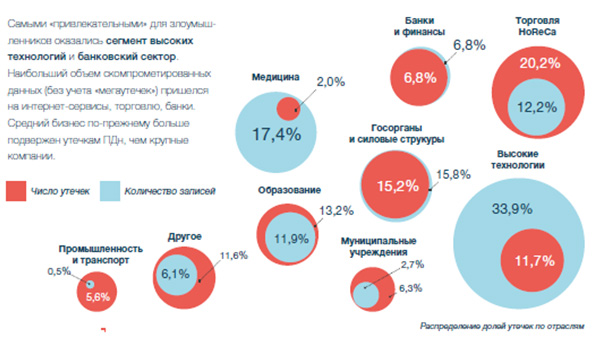
Чаще всего утечки происходили в организациях медицинской сферы, реже всего — в сегменте промышленности и транспорта. Наибольший объем скомпрометированных записей пришелся на сектор высоких технологий, включая интернет-сервисы и крупные порталы. Утечки из госорганов составили около16% от общего объема скомпрометированных записей.
В первом полугодии 2017 года наибольший интерес злоумышленники проявляли к банкам и компаниям высокотехнологичного сегмента. В этих отраслях более 50% утечек ПДн носили умышленный характер.
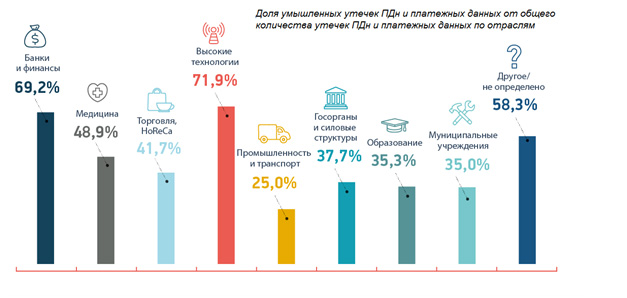
«Коммерческие и государственные сервисы обрабатывают все больше данных в электронном виде, и такие данные крайне ликвидны, — отметил Сергей Хайрук. — Сектор высоких технологий очень сильно подвержен утечкам информации, как и финансово-кредитная сфера. Эти отрасли вызывают наибольший интерес со стороны злоумышленников — в них большая часть данных была скомпрометирована умышленно. И это как раз те сегменты, которые являются драйверами цифровой экономики, с развитием которой нужно уделять особое внимание вопросам регулирования и информационной безопасности процессов цифровой трансформации».






