







Эксперты «Лаборатории Касперского» обнаружили троянца, который выдает себя за генератор ключей для персональных продуктов компании. Запустив зараженный программный файл kaspersky.exe, пользователь выбирает из представленного списка продукт для взлома. После этой процедуры зловред якобы начинает генерировать требуемый ключ.
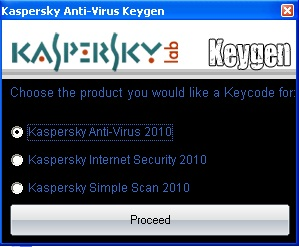
На самом деле фальшивый генератор тайком устанавливает и запускает две вредоносные программы - сообщают эксперты. Одна из них крадет пароли к онлайн-играм и регистрационные данные от установленного на компьютере легального ПО. Вторая действует как кейлоггер, отслеживая введенную через клавиатуру информацию, а также открывает киберпреступникам доступ к зараженному ПК.
Таким образом, запустив на компьютере этот «генератор ключей», пользователь заражает систему сразу несколькими вредоносными программами и фактически передает его в руки злоумышленников.
«Лаборатория Касперского» рекомендует воздерживаться от запуска сомнительных программ, а также напоминает, что только лицензионные продукты компании обеспечивают полноценную защиту от информационных угроз.






