








Команда вымогателей Industrial Spy опробует новый рычаг давления — сайт очередной жертвы подвергся взлому, на нем теперь красуется записка с требованием выкупа. Обычно все переговоры в таких случаях ведутся закулисно, и даже акты запугивания неплательщиков (вроде адресных рассылок и DDoS) не выносятся на публику, чтобы угроза потери репутации возымела искомый эффект.
Группировка Industrial Spy — новый игрок на рынке; вначале она просто воровала данные у организаций и в случае неуплаты выкупа выставляла их на продажу в сети Tor. Позднее новоявленные вымогатели обзавелись собственным шифровальщиком и начали рекламировать свою торговую площадку в записке о выкупе (README.txt), оставляемой на зараженных машинах, — видимо, чтобы жертвы могли за отдельную плату вернуть свои секреты, пока ими не завладели конкуренты.
Вчера шантажисты начали продавать информацию, якобы украденную у французской компании SATT Sud-Est. Они также разместили на сайте жертвы сообщение о краже свыше 200 Гбайт данных, которые будут распроданы, если законный владелец не заплатит выкуп.
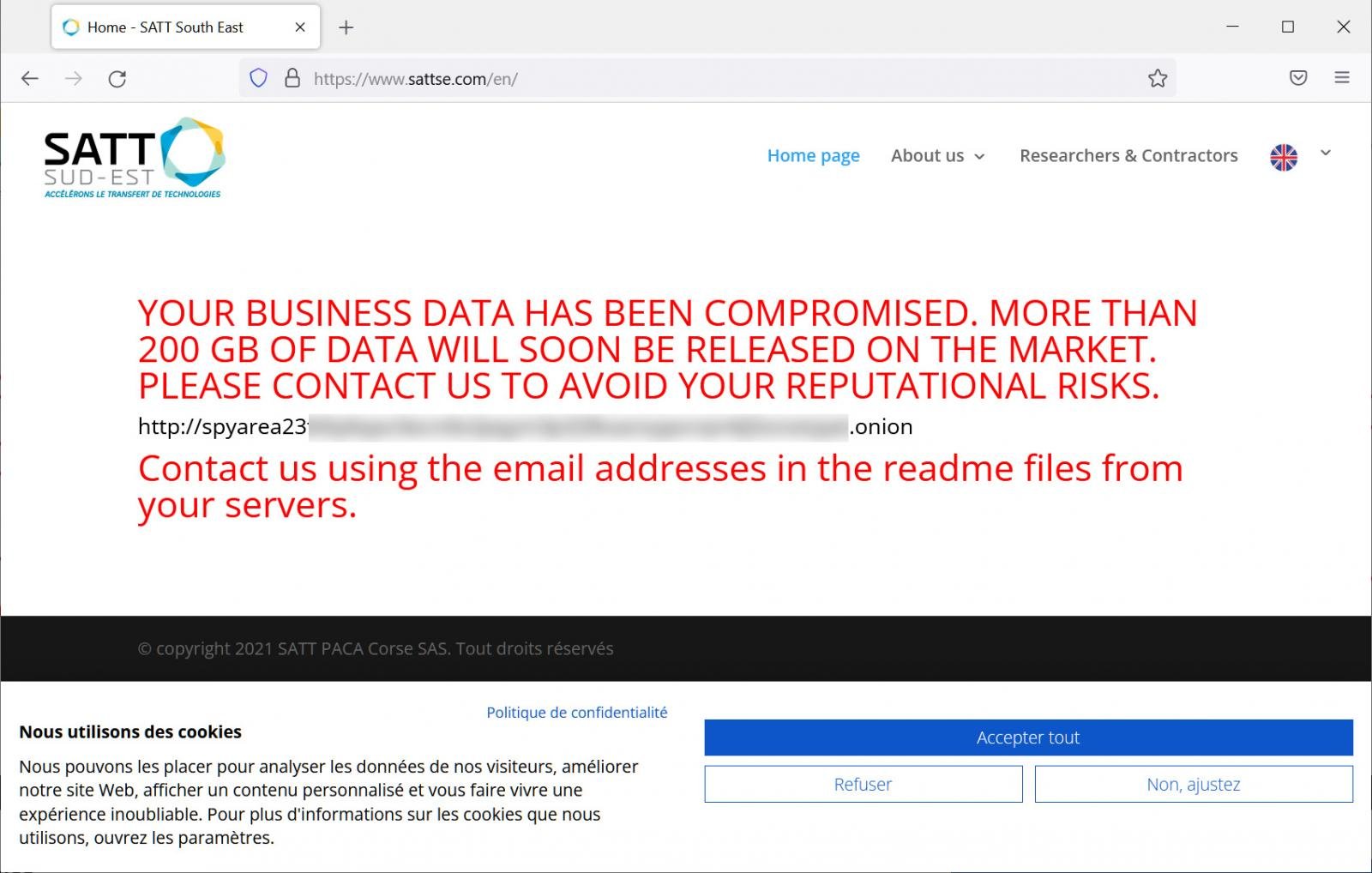
По данным BleepingComputer, это первый случай использования дефейса как средства вымогательства. Эксперты полагают, что новая тактика не получит широкого распространения: веб-серверы обычно хостятся не в корпоративных сетях, а у профильных провайдеров. В этом случае хакерам придется отыскать уязвимость на сайте или получить доступ к учетным данным организации в ходе кражи данных из ее внутренних сетей.
Появление нестандартных тактик в арсенале вымогателей может свидетельствовать о снижении эффективности этого криминального промысла. Чтобы добиться своего, современные шантажисты даже готовы выйти из тени с риском раскрыть себя и привлечь внимание правоохранительных органов.
Так, еще одна молодая кибергруппа, LAPSUS$, объявила открытый конкурс для инсайдеров, способных предоставить доступ к сетям своих работодателей, а также устраивает в Telegram голосование при выборе очередной жертвы. Столь вызывающее поведение привело к тому, что в ИБ-сообществе на некоторых членов хакерской группировки уже копятся досье.






