







Британские и американские спецслужбы опубликовали совместный алерт о ботнете Cyclops Blink, составляющем угрозу для сетевых устройств класса SOHO. Используемый ботоводами модульный Linux-зловред поразил уже более 1,5 тыс. файрволов WatchGuard FireBox в 70 странах и в любой момент может быть переориентирован на другие платформы и прошивки.
По имеющимся данным, вредонос Cyclops Blink объявился в интернете в июле 2019 года, а может, и ранее. Анализ образцов показал, что это более продвинутая версия VPNFilter, которую предположительно создали те же умельцы (APT28, она же Fancy Bear, Sandworm и Sofacy).
Основными задачами Cyclops Blink являются сбор и слив на сторону информации о зараженном устройстве, а также загрузка и запуск дополнительных файлов. Зловред распространяется через эксплойт, устанавливается в систему под видом обновления прошивки и остается там даже после перезагрузки.
Все известные жертвы — исключительно WatchGuard FireBox, устройства безопасности класса UTM на процессорах PowerPC 32-бит со вшитыми ключами аутентификации HMAC. Примечательно, что все они используют кастомные настройки — внешний доступ к интерфейсу удаленного управления во всех случаях оказался включенным.
Обмен с C2-серверами Cyclops Blink осуществляется с использованием RSA-шифрования. Подробный разбор угрозы выложен отдельным документом (PDF) на сайте британского центра кибербезопасности (National Cyber Security Centre, NCSC).
На данный момент наблюдатели из Shadowserver зафиксировали 1573 случая инфицирования в 70 странах (уникальные IP-адреса в 495 различных AS-сетях). Больше половины зараженных устройств находятся в США, Франции, Италии, Канаде или Германии.
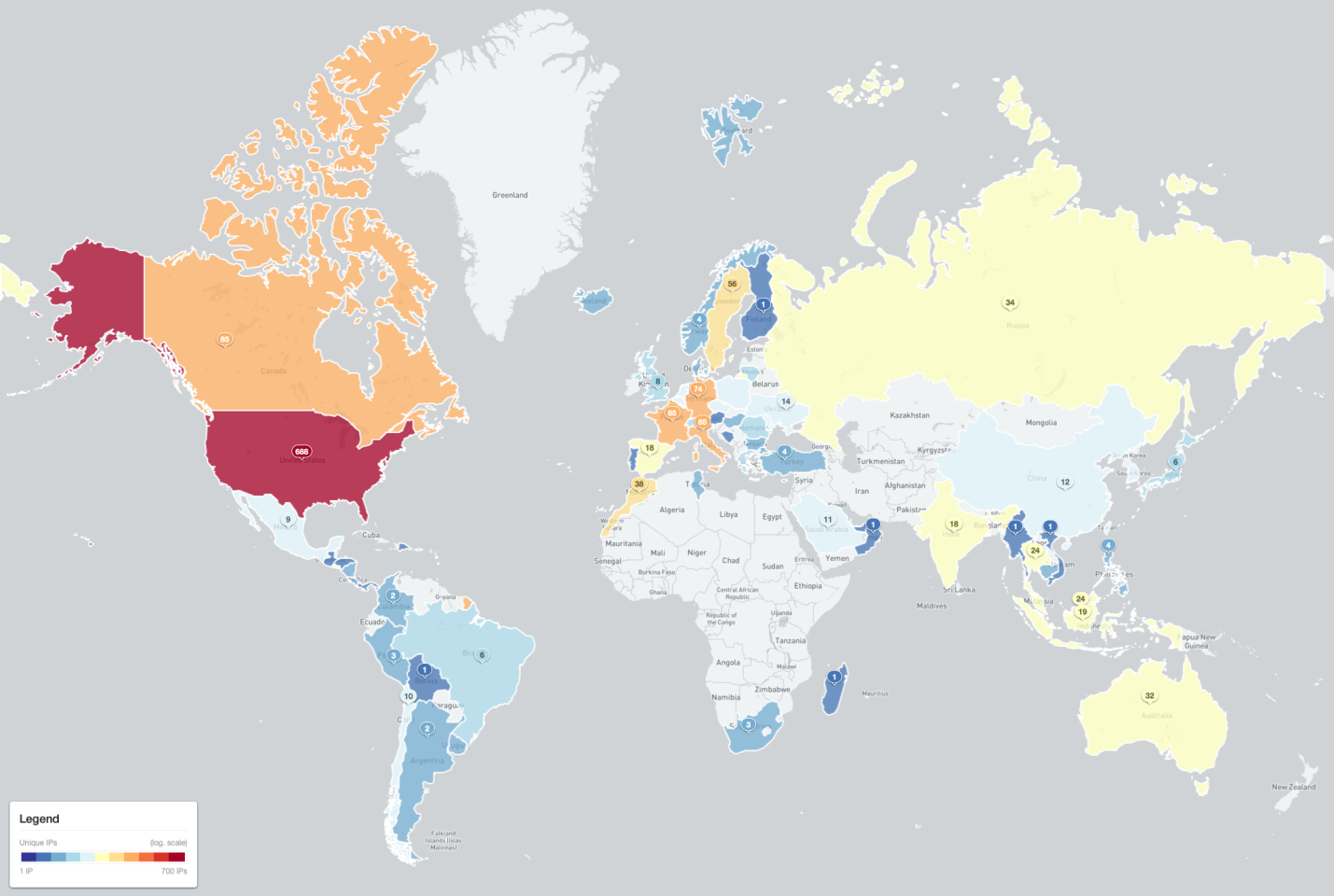
Выявлены также 25 командных серверов Cyclops Blink. Они подняты в сетях 25 AS-провайдеров в семи странах (8 в Италии, 6 в США, по 4 в Германии и Франции, по одному в Марокко, Саудовской Аравии и на Кипре).
По данным WatchGuard, данная угроза актуальна для примерно 1% ее устройств. Во избежание неприятностей производитель рекомендует таким пользователям вернуть дефолтные настройки, а в случае заражения незамедлительно сменить все хранящиеся на устройстве пароли.






