














В OpenClaw нашли сразу три серьёзные уязвимости, которые позволяли красть учетные данные, повышать привилегии и выполнять произвольный код в системе, где запущен ИИ-ассистент. Две ошибки получили оценку 8,8 из 10 по шкале CVSS.
Они были связаны с фильтрацией команд: защитный механизм блокировал не все опасные входные данные, поэтому злоумышленник мог протащить системную команду туда, где ей быть совсем не положено.
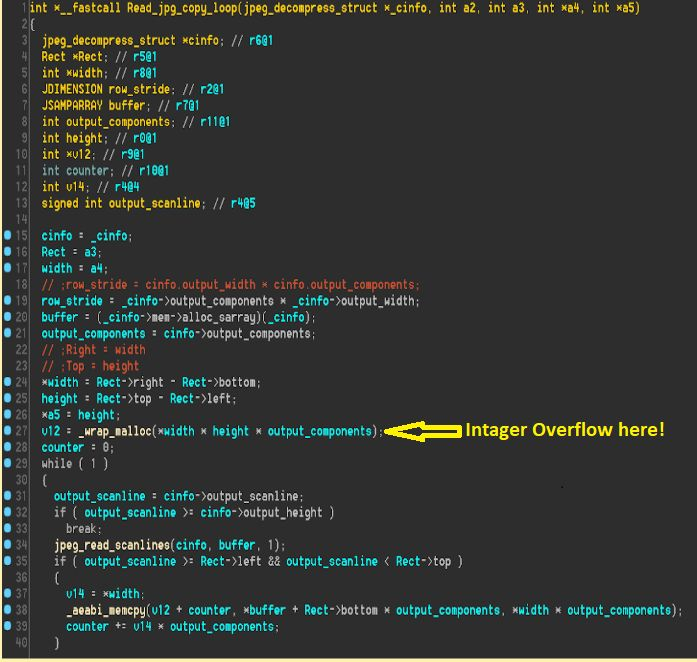
Третья уязвимость с рейтингом 8,4 позволяла обходить ограничения песочницы через монтирование родительских каталогов. OpenClaw запрещал прямой доступ к папкам вроде ~/.ssh, ~/.aws и ~/.gnupg, но при этом мог разрешить подключить весь каталог /home. После этого SSH-ключи, облачные токены и GPG-секреты оказывались буквально на столе.

Еще веселее с /var: через него атакующий мог добраться до сокета Docker и выбраться из песочницы прямо на хост.
Исследователь Чинмохан Наяк утверждает, что атаку можно было запустить внешним сообщением через WhatsApp (принадлежит корпорации Meta, признанной экстремистской и запрещённой в России) без предварительного доступа к системе. В худшем сценарии злоумышленник получал данные, закреплялся в системе и выполнял код на машине владельца.

Разработчики закрыли все три дыры в OpenClaw 2026.6.6. Пользователям советуют срочно обновиться, включить песочницу для всех второстепенных сессий, убрать exec из разрешенных инструментов и максимально сузить списки доверенных каналов.



