













Любите скачивать красивые обои для рабочего стола через Steam Workshop? Возможно, вместе с ними можно было получить весьма неприятный бонус. Исследователи из «Лаборатории Касперского» обнаружили кампанию по распространению вредоносных программ через Steam Workshop — площадку Valve для публикации пользовательского контента.
Злоумышленники прятали зловреды внутри обоев для популярного приложения Wallpaper Engine.
Проблема связана с одной из функций Wallpaper Engine. Помимо обычных изображений и видео приложение поддерживает так называемые Application Wallpapers — полноценные исполняемые программы Windows, которые могут запускаться прямо в качестве обоев рабочего стола.
Этим и воспользовались атакующие. По данным исследователей, как минимум с конца 2025 года в Steam Workshop начали появляться вредоносные обои, которые после установки запускали скрытые процессы на компьютере пользователя. Некоторые из таких файлов скачали тысячи и даже десятки тысяч человек.
В одном из изученных случаев под видом игры NTRaholic распространялся бэкдор семейства DarkKomet. Пользователь видел обычное приложение, однако параллельно на компьютер устанавливались дополнительные компоненты для кражи данных Steam-аккаунта.
Но этим дело не ограничивалось. Эксперты обнаружили образцы со стилерами Lumma и Vidar, криптомайнерами, загрузчиками ботнетов, RanEngine и даже программами-вымогателями.
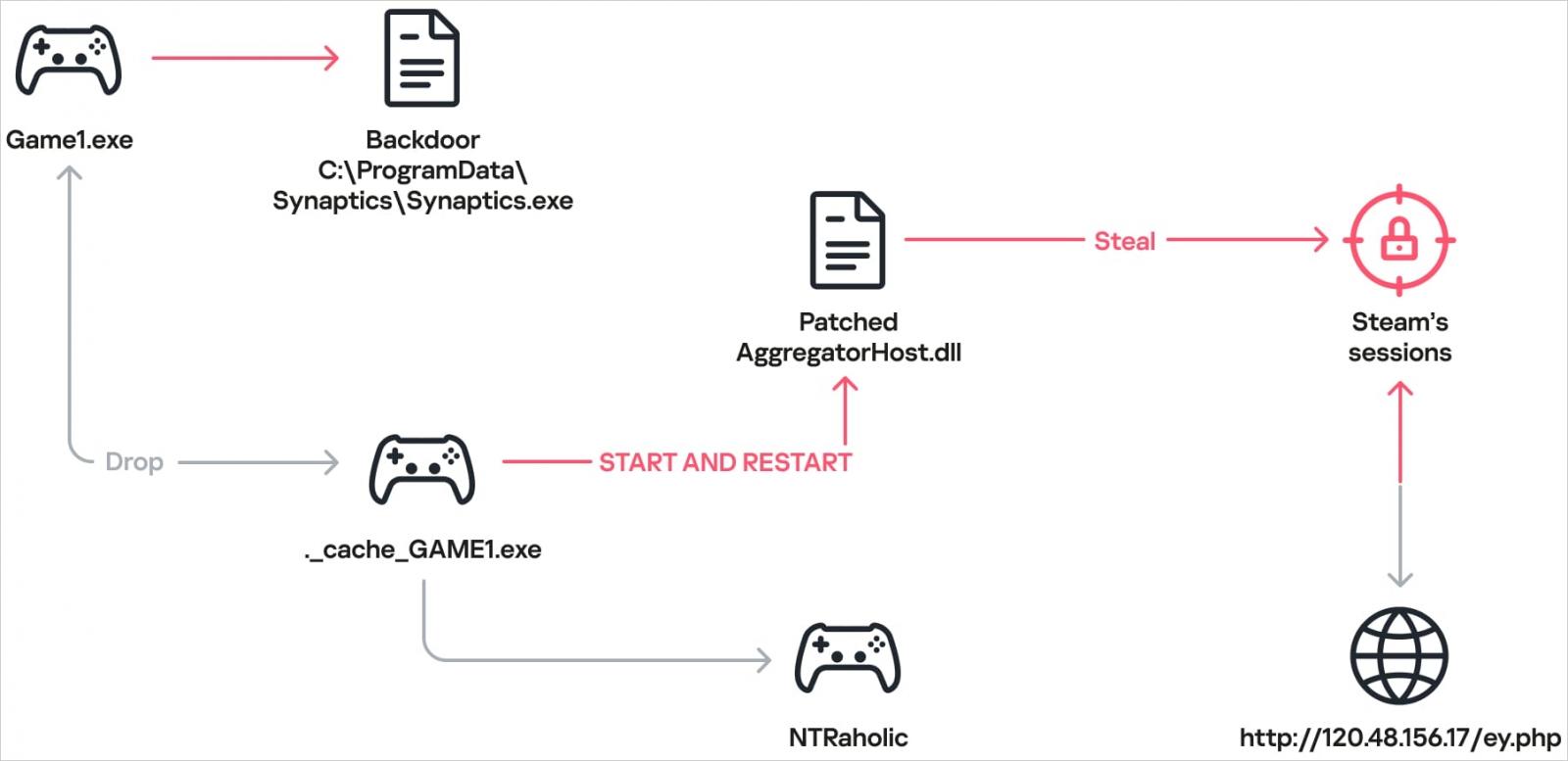
Часть вредоносных файлов была спрятана внутри защищённых паролем архивов. Пользователя убеждали самостоятельно открыть архив и запустить содержимое, после чего заражение происходило практически незаметно.
Главной целью злоумышленников часто становились именно аккаунты Steam. Вредоносные библиотеки искали сохранённые данные учётных записей и передавали их атакующим.
После уведомления исследователей Valve удалила обнаруженные вредоносные публикации из Steam Workshop. Однако специалисты предупреждают, что новые заражённые обои могут появиться снова.



