














Жителям Москвы снова стоит приготовиться к перебоям с мобильным интернетом. Ряд операторов уже разослал своим абонентам уведомления о том, что сегодня в отдельных районах столицы возможны ограничения доступа к Сети. Как следует из сообщений, меры вводятся по соображениям безопасности.
При этом, как пишет «Код Дурова», речь не идёт о полном отключении интернета по всему городу, ограничения затронут лишь отдельные зоны.
Пока городские власти официально ситуацию не комментировали. Не уточняется и то, сколько продлятся ограничения, а также какие именно районы окажутся под их действием.
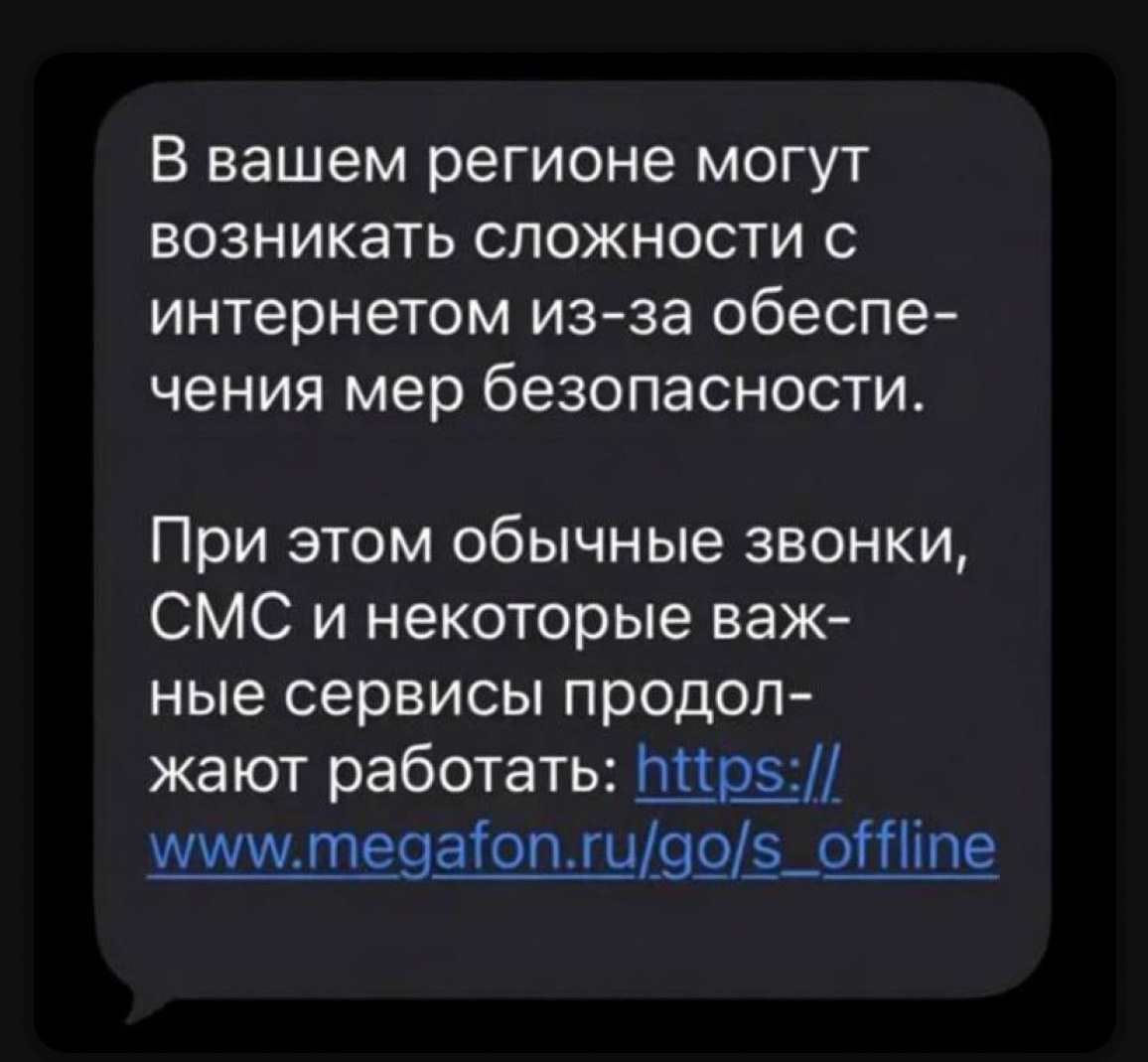
Для москвичей подобные сообщения перестают быть неожиданностью. Во время временного отключения мобильного интернета могут возникать сложности с вызовом такси, оплатой через терминалы, работой банковских приложений, сервисов доставки и других онлайн-платформ, зависящих от мобильной передачи данных.
Если доступ к Сети пропал, специалисты рекомендуют по возможности подключиться к Wi-Fi, заранее скачать необходимые карты и документы, а также иметь при себе наличные или банковскую карту на случай, если бесконтактная оплата временно перестанет работать.
Когда мобильный интернет вернётся к обычному режиму работы, пока неизвестно.
Ранее Памфилова призвала россиян не роптать из-за отключений интернета.



