














Любите красивые анимированные обои для новой вкладки Chrome? Есть плохие новости. Исследователи из Unit 42 обнаружили масштабную кампанию Gameograf, в рамках которой более 50 расширений для браузера маскировались под безобидные инструменты с живыми обоями, а на деле превращали браузер в рекламную площадку злоумышленников.
По оценкам специалистов, жертвами схемы стали около 30 тысяч пользователей.
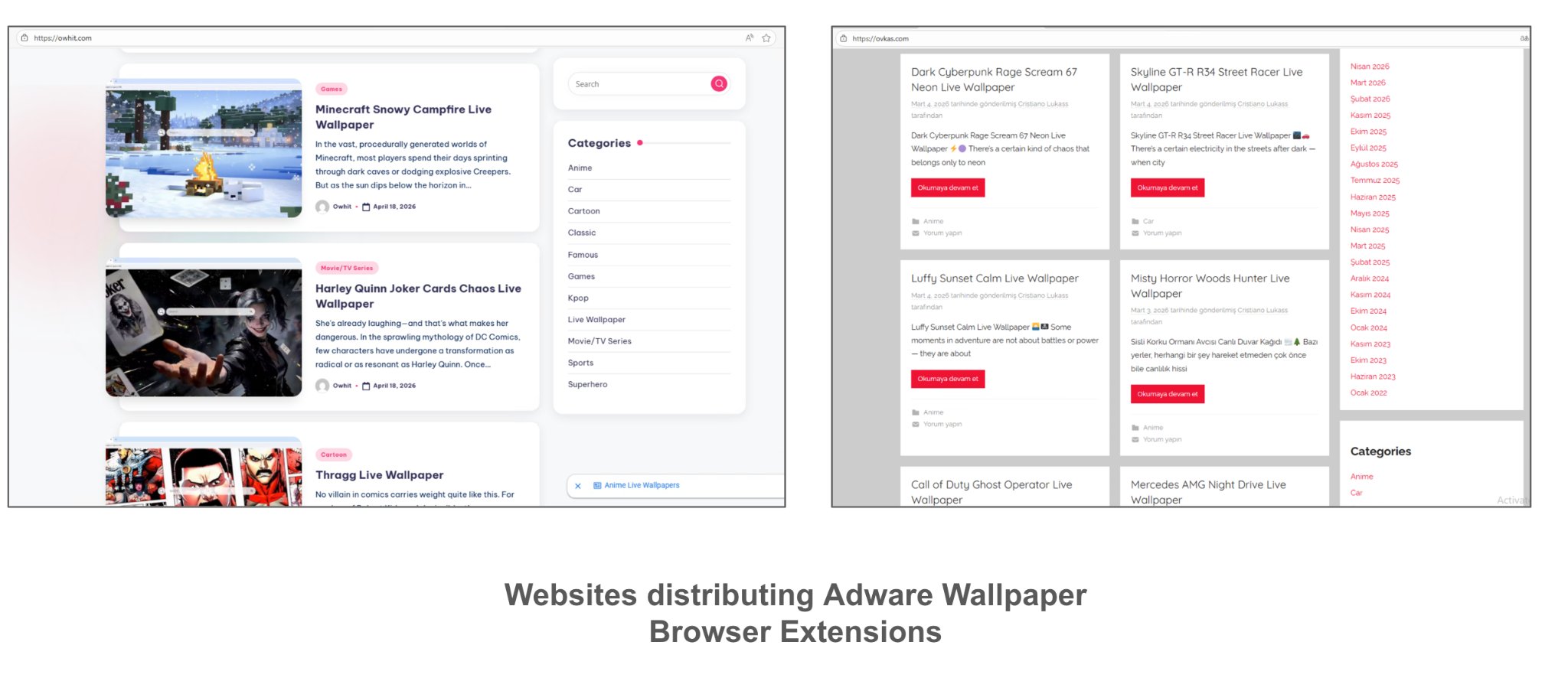
Расширения распространялись через Chrome Web Store и сторонние сайты, посвящённые обоям, темам оформления и кастомизации браузера. Пользователям обещали эффектные анимированные фоны и стильные новые вкладки, но после установки начиналось совсем другое шоу.
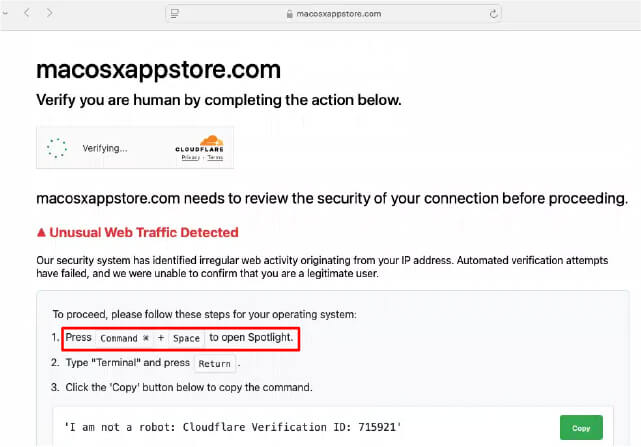
Получив необходимые разрешения, расширения принудительно открывали новые вкладки, перенаправляли пользователей на рекламные страницы и загружали контент с серверов операторов кампании.
Причём большая часть логики работала удалённо: злоумышленники регулярно подгружали HTML-код и настройки со своей инфраструктуры, не публикуя новые версии расширений в магазине Chrome.
Фактически операторы могли в любой момент менять рекламу, ссылки, всплывающие окна и сценарии перенаправления.
Особую тревогу исследователей вызвал механизм удалённой загрузки HTML-контента без какой-либо фильтрации. Сегодня через него показывается реклама, а завтра ту же схему можно использовать для фишинга, поддельных окон авторизации или доставки других вредоносных компонентов.
Для дополнительной маскировки расширения регулярно очищали локальные базы данных браузера IndexedDB. Это помогало сбрасывать состояние и затрудняло анализ происходящего.
Основными жертвами кампании стали обычные пользователи, геймеры и поклонники популярных игровых и медиафраншиз, которые искали тематические обои для браузера.
В результате пользователи сталкивались с навязчивой рекламой, постоянными редиректами, самопроизвольным открытием вкладок и ухудшением производительности браузера.
Эксперты рекомендуют проверить список установленных расширений и удалить подозрительные дополнения с живыми обоями или кастомными стартовыми страницами. Особенно если они требуют широкие разрешения и активно взаимодействуют с внешними сайтами.



