















Google готовит глобальный запуск Play Age Signals API — инструмента, который позволит приложениям узнавать примерный возраст пользователя и подстраивать под него контент. Паспорт показывать не придётся: вместо даты рождения разработчики получат один из четырёх диапазонов — 0-12, 13-15, 16-17 или 18+.
Получив такой сигнал, приложение сможет изменить доступные функции, отфильтровать контент или хотя бы разговаривать с ребёнком не так, как со взрослым.
Это обратная сторона родительского контроля: Family Link не просто закрывает детям неподходящие приложения, а Age Signals помогает самим приложениям вовремя переключиться в детский режим.
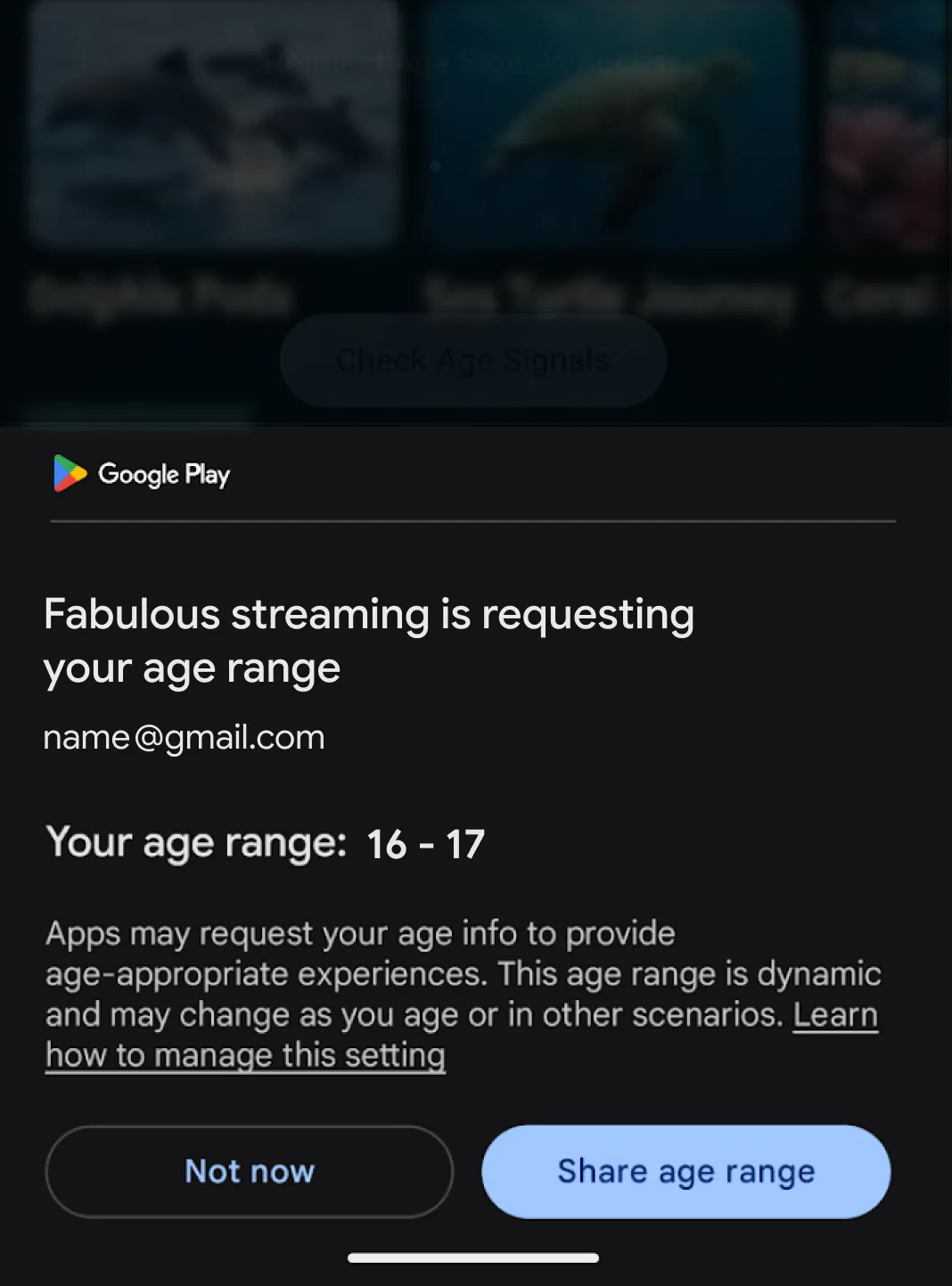
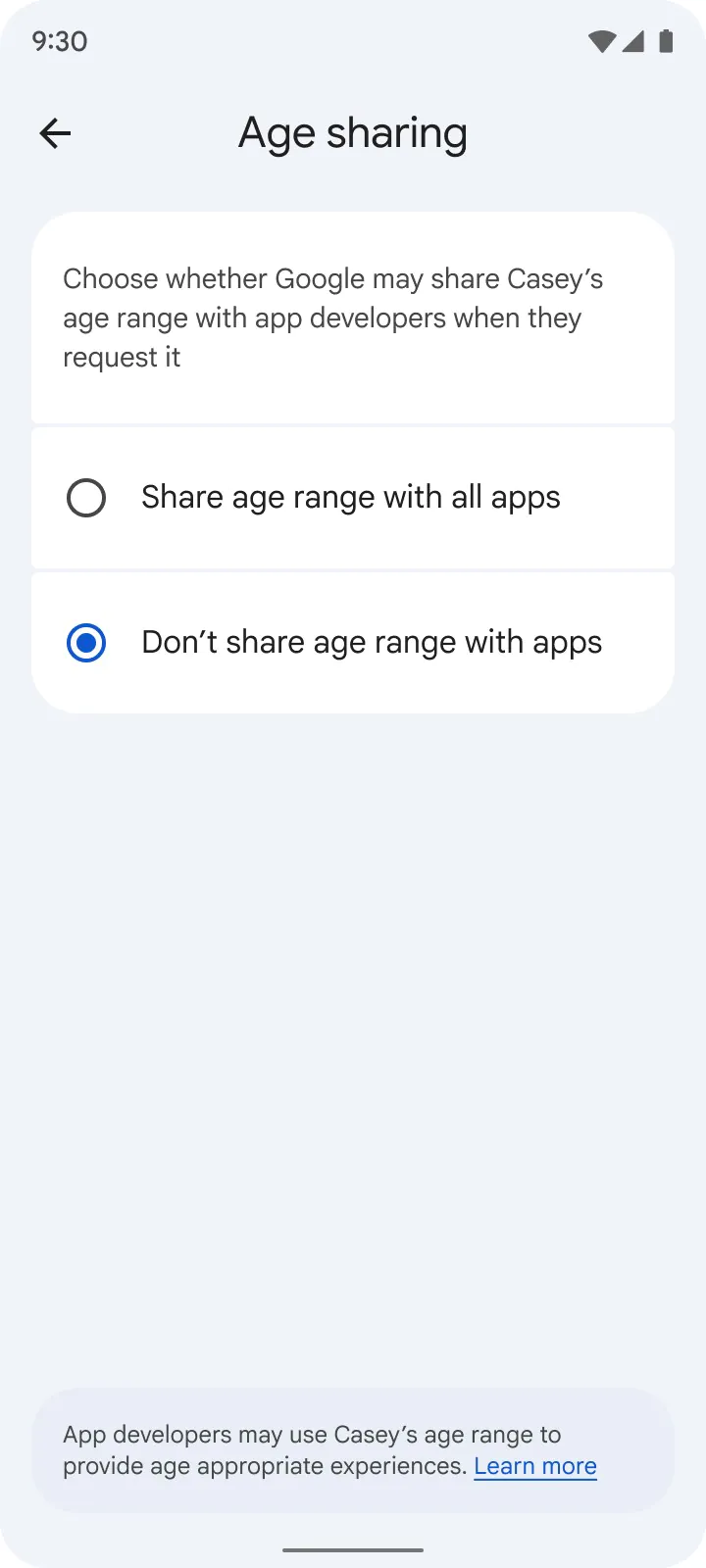
Раздавать возраст направо и налево Google не собирается. Пользователи смогут решать, каким приложениям разрешено получать эту информацию, а родители — полностью отключить её передачу. Точные персональные данные разработчикам при этом не раскрываются.
Компания также установила жёсткие правила использования API. Возрастные диапазоны разрешено применять только для создания подходящего пользователю интерфейса и контента. Превращать их в новый инструмент рекламного таргетинга или аналитики нельзя. По крайней мере, на бумаге лазейку сразу закрыли.
Сейчас Age Signals API уже доступен разработчикам в Бразилии. В ближайшие недели Google расширит программу на Канаду и Австралию, а до конца года планирует запустить её по всему миру.
Поддерживать API разработчики будут добровольно, поэтому мгновенно взрослеть и молодеть все приложения не начнут. Но инструмент у них появится полезный: узнать не день рождения пользователя, а лишь то, стоит ли показывать ему взрослый интернет во всей его красе.



