








Правительственная хакерская группировка APT35 (также Charming Kitten или Phosphorus), за которой якобы стоят власти Ирана, запустила кибератаки, устанавливающие на компьютеры жертв PowerShell-бэкдор. Примечательно, что в этой кампании злоумышленники эксплуатируют уязвимость Log4Shell, всколыхнувшую мир ИБ под конец прошлого года.
Модульный пейлоад, фигурирующий в новых атаках, может поддерживать связь с командным сервером (C2), а также получать, расшифровывать и загружать дополнительные модули для расширения функциональности.
Используемый эксплойт Log4Shell предназначен для уязвимости CVE-2021-44228, которую выявили в декабре 2021 года в библиотеке для логирования — Apache Log4j. Как отметили специалисты Check Point, APT35 одной из первых взяла в оборот эксплойт, пока ещё не все успели установить выходящие патчи.
Спустя считаные дни после раскрытия информации о Log4Shell иранские хакеры уже вовсю сканировали Сеть на наличие уязвимых систем. Check Point, с самого начала наблюдавшая за этими атаками, отметила уже известную инфраструктуру CharmPower, которая раньше встречалась в кампаниях киберпреступной группировки.
В случае успешной эксплуатации CVE-2021-44228 злоумышленники устанавливают в систему жертвы модульный бэкдор, запуская PowerShell-команду с зашифрованным base64 пейлоадом. Далее на устройство устанавливается модуль из хранилища Amazon S3 Bucket, принадлежащего APT35.
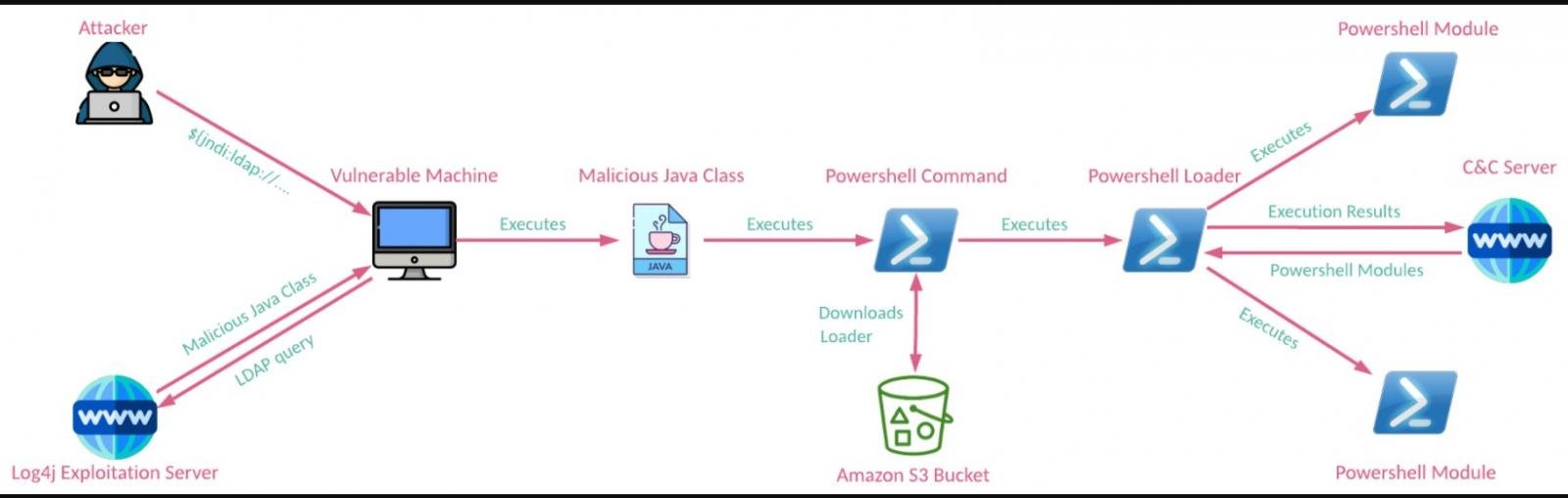
Среди ключевых функций вредоносной программы исследователи отмечают следующие:
- Валидация сетевого соединения. После запуска скрипт ждёт активного интернет-соединения, отправляя запросы HTTP POST домену google.com с параметром hi=hi.
- Сбор информации о системе. Скрипт записывает версию Windows, имя компьютера и контент файла Ni.txt, хранящегося в каталоге $APPDATA.
- Получение адреса C2-домена. Вредонос декодит C2-домен из жёстко заданного в коде URL — hxxps://s3[.]amazonaws[.]com/doclibrarysales/3. Ссылка хранится в том же «ведре» S3, что и сам бэкдор.
- Получение, расшифровка и выполнение дополнительных модулей.
Напомним, что в прошлом месяце киберпреступники проникли на рабочий сервер компании Onus через уязвимость Log4Shell и смогли утащить из ведра Amazon S3 данные 2 миллионов клиентов.






