







Twitter-аккаунт, который ранее связывали с защищённым мессенджером An0m от ФБР, на этой неделе начал публиковать интересные твиты. Всё выглядело так, будто некий шутник получил доступ или взломал эту учётную запись.
Напомним, что An0m представлял собой фейковый зашифрованный мессенджер от ФБР, который был создан специально для глобальной операции «Operation Ironside», организованной спецслужбами США и Австралии.
Основная цель An0m заключалась в поиске киберпреступников, которые бы клюнули на уловку «защищённого общения» в специально созданном мессенджере. Летом мы писали, что с помощью An0m правоохранителям удалось перехватить личные переписки членов кибергруппировок.
На странное поведение Twitter-аккаунта An0m обратили внимание представители BleepingComputer. Например, в строке био теперь указано: «мы не федеральные агенты».
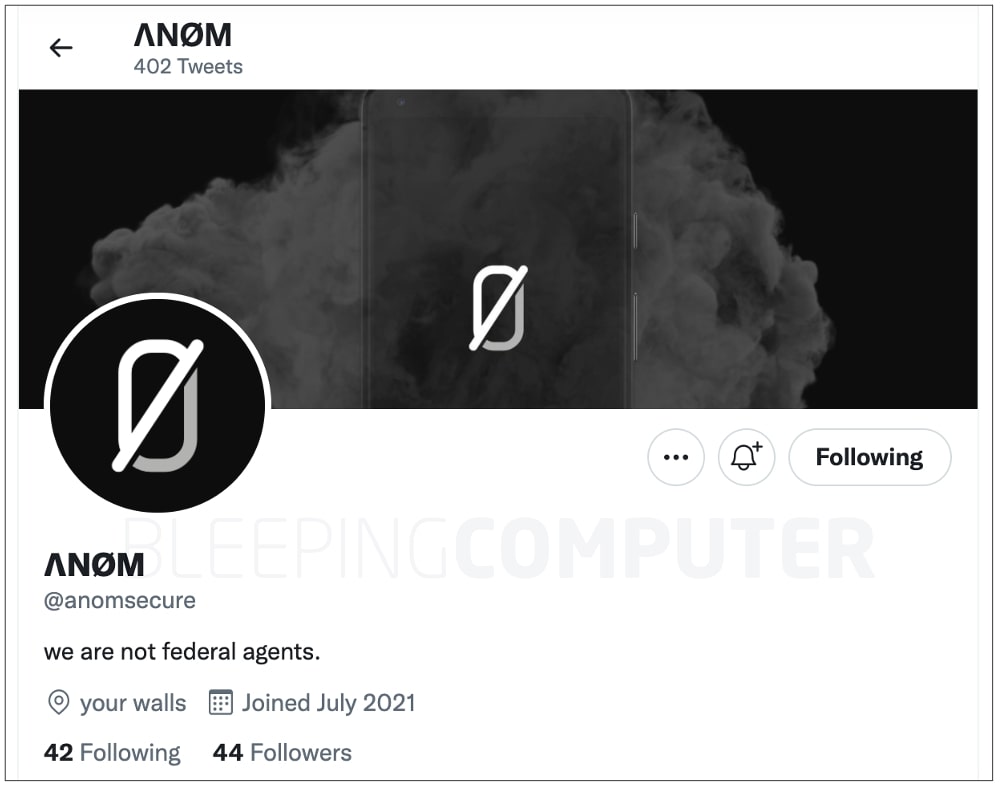
«Кто-то получил контроль над аккаунтом ΛNØM, зашифрованном сервисе для обмена сообщениями, который ранее использовался в операции правоохранительных органов. Теперь твиты этой учётки гласят, что ΛNØM — не федеральные агенты», — пишет Мэттью Хики (Hacker Fantastic), сооснователь Hacker House.
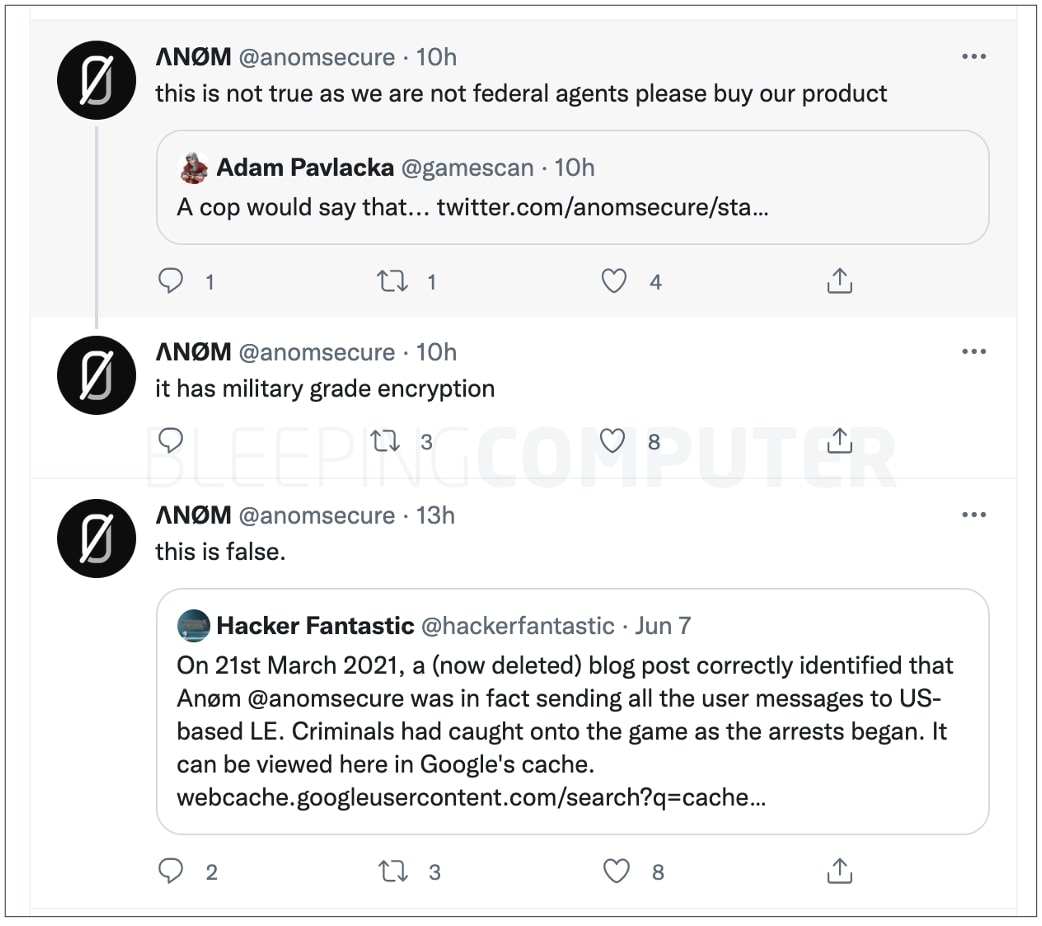
Пока неизвестно, что именно стало причиной такого поведения Twitter-аккаунта, однако вполне логично звучит теория о том, что некто просто завёл то же имя, что было у оригинальной учётной записи.



