







Исследователи обнаружили незащищённый сервер, на котором лежали семь гигабайт незашифрованных файлов. Среди общедоступной информации были 350 миллионов записей с уникальными адресами электронной почты.
Открытые данные обнаружила команда CyberNews, установить владельца сервера на данный момент не удалось. Все незащищённые данные хранились в ведре Amazon S3, любой желающий мог беспрепятственно скачать их.
Всего на сервере Amazon AWS лежали 67 файлов. 14 из которых были хешированными. Однако исследователи нашли семь полностью открытых CSV-файлов. В них содержались 50 млн записей уникальных адресов электронной почты, принадлежащих, вероятно, американским пользователям.
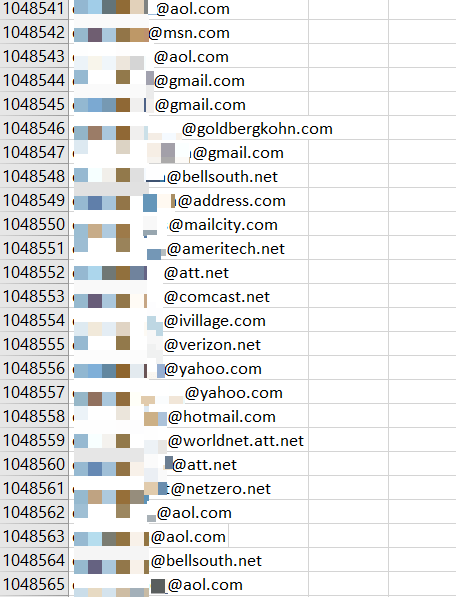
В общей сложности в файлах можно было найти 350 миллионов имейлов, как в хешированном, так и в открытом виде. Если отталкиваться от временных меток на сервере, некто заливал файлы в ведро поэтапно: сначала хешированные, в самом конце — открытые.
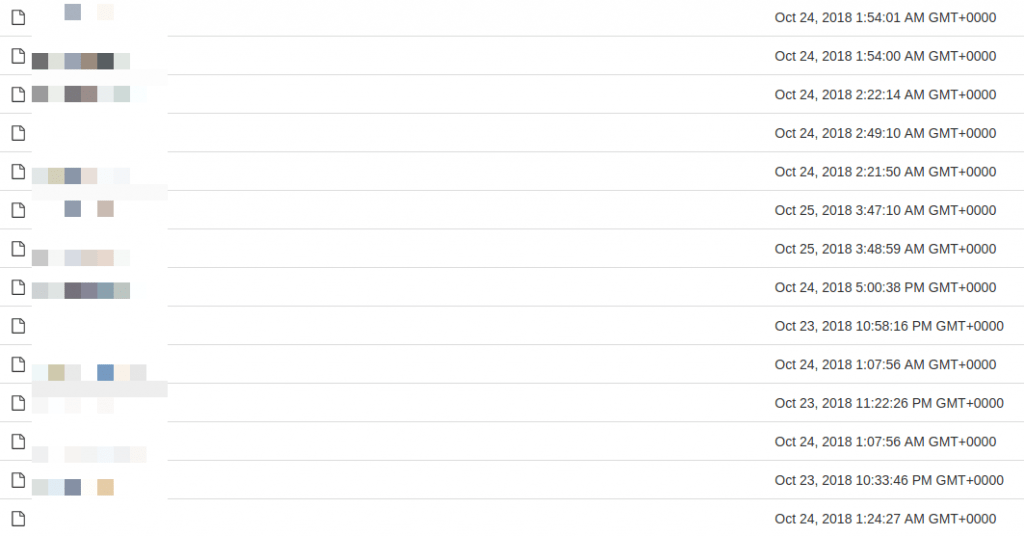
Специалисты предполагают, что неизвестный владелец сервера взял все данные на чёрных онлайн-рынках ещё в октябре 2018 года. Пока непонятно, поучили ли другие киберпреступники доступ к этой информации.






