














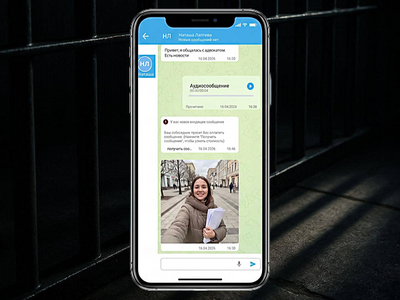
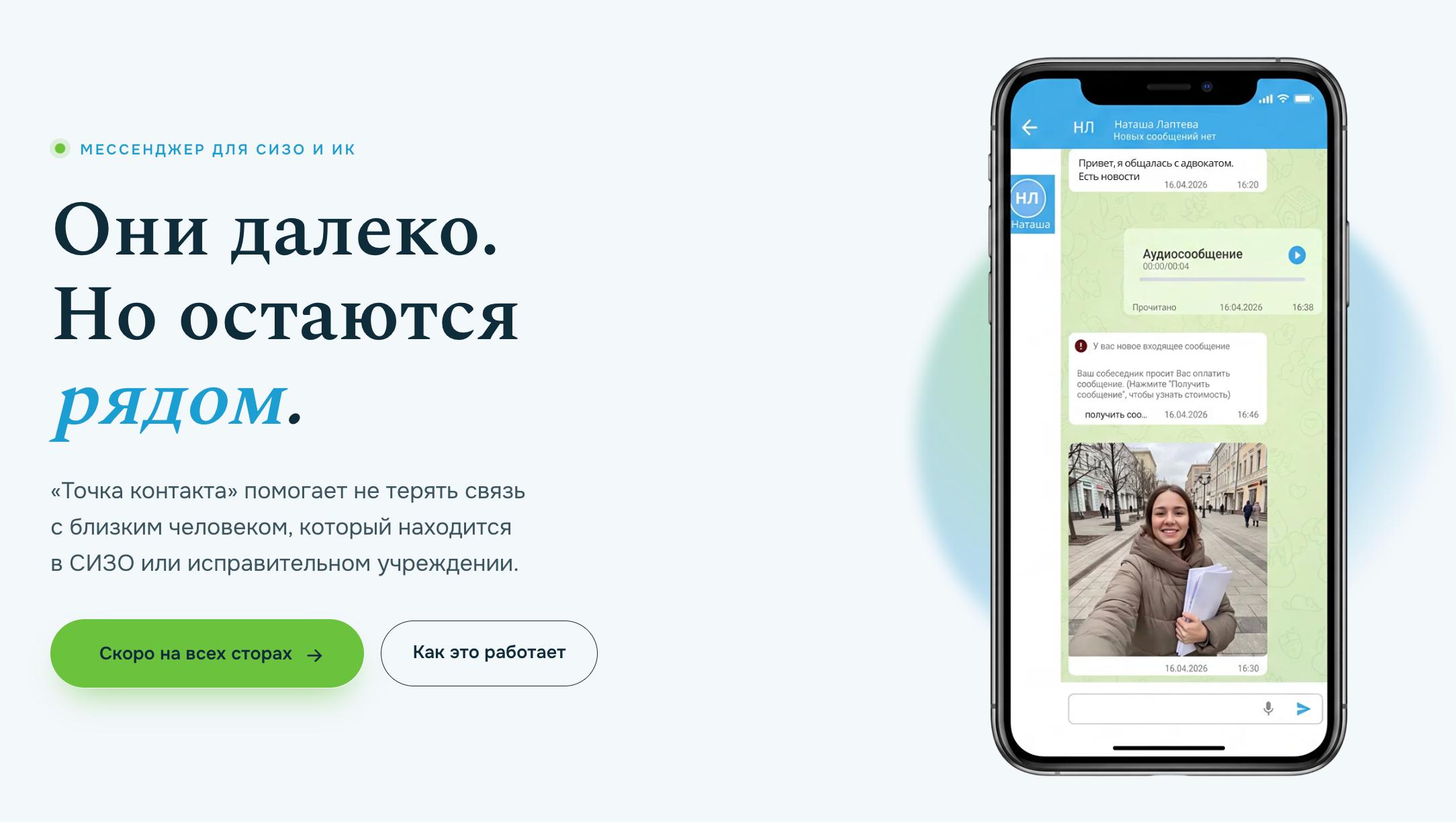
В России появился мессенджер для связи с людьми, которые находятся в СИЗО и исправительных учреждениях. Сервис называется «Точка контакта» и позволяет отправлять сообщения, фотографии, видео и голосовые записи. Правда, привычного написал и забыл здесь не будет, почти каждое действие оплачивается отдельно.
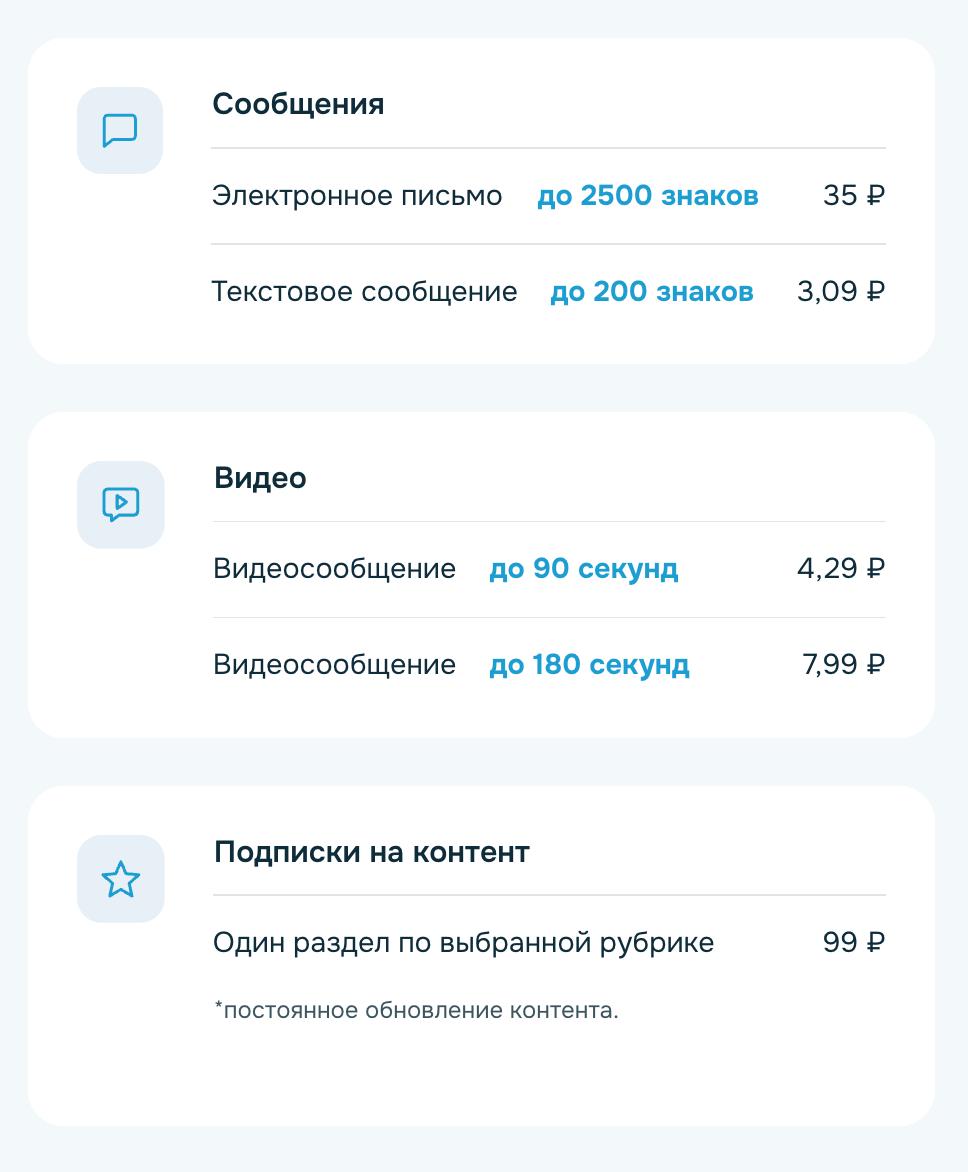
Электронное письмо объёмом до 2500 знаков стоит 35 рублей. Короткое текстовое сообщение до 200 знаков — 3,09 рубля.
За видеосообщение продолжительностью до 90 секунд просят 4,29 рубля, до 180 секунд — 7,99 рубля. Отправка одного голосового сообщения, по данным телеграм-канала «Банки, деньги, два офшора», обойдётся примерно в 7 рублей.
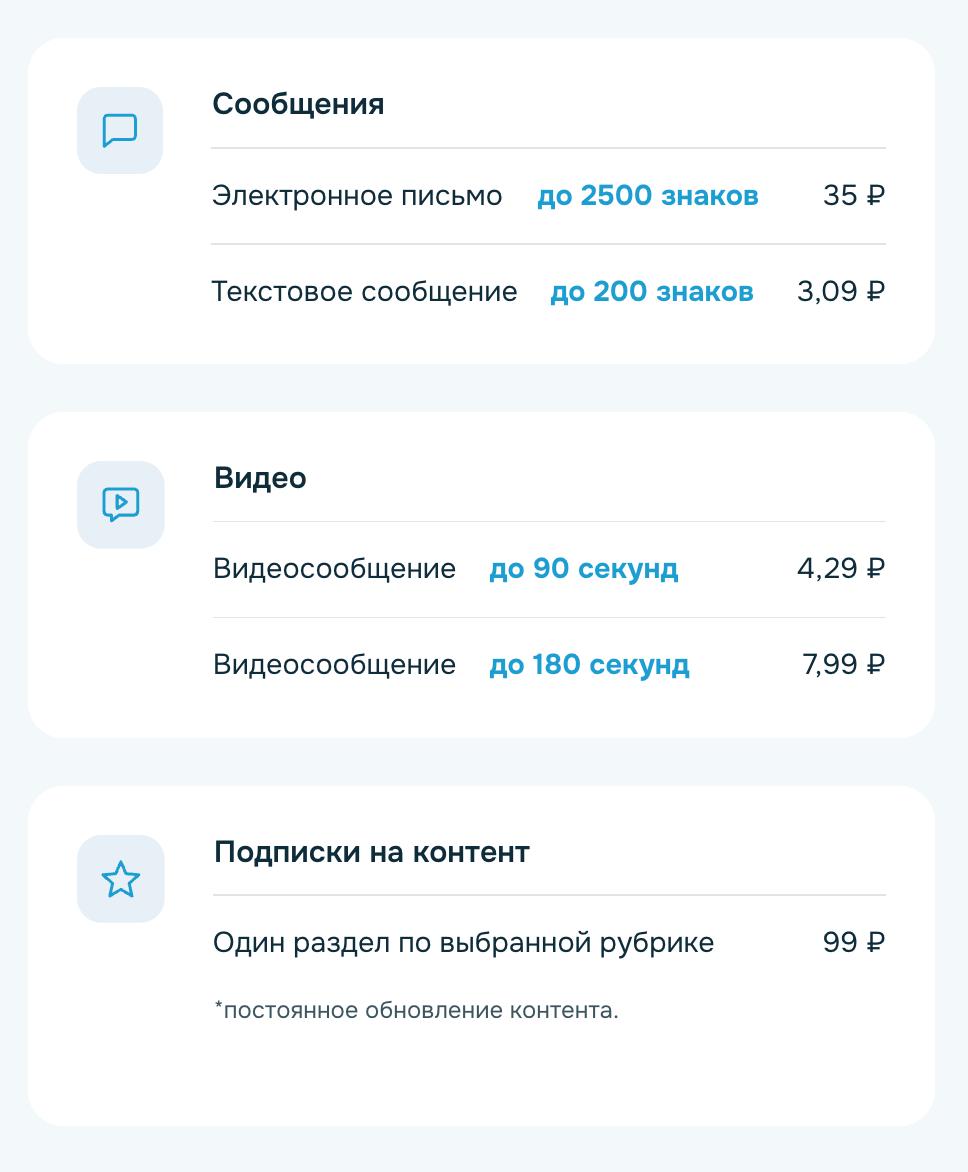
Сервис также предлагает платные подписки на контент. Один раздел по выбранной рубрике с постоянным обновлением стоит 99 рублей.
На сайте проекта говорится, что платформа должна помочь родственникам и близким поддерживать связь с человеком в СИЗО или колонии. В интерфейсе показаны обычные чаты с текстом, аудио, фотографиями и уведомлениями об оплате входящих сообщений.
Пока сервис обещают запустить во всех магазинах приложений. Детали о том, кто именно выступает оператором платформы, как проходит проверка сообщений и во всех ли учреждениях она будет доступна, не раскрываются.
Получился мессенджер с весьма буквальным тарифом на общение: хочешь написать близкому человеку — сначала посчитай символы.



