














Google добавила в Chrome для Android новую настройку конфиденциальности: теперь сайтам можно передавать не точную, а примерную геолокацию. Это удобно для случаев, когда сервису не нужен ваш конкретный адрес или координаты до улицы.
Раньше всё было жёстче: если сайт просил доступ к местоположению, пользователь фактически делился точными данными. Даже если речь шла о простых вещах вроде прогноза погоды, местных новостей или регионального контента.
Теперь Chrome позволит выбрать более мягкий вариант — показать сайту только приблизительный район. По словам менеджера продукта Chrome Арчита Агарвала, это должно дать пользователям больше контроля над тем, какими данными они делятся.
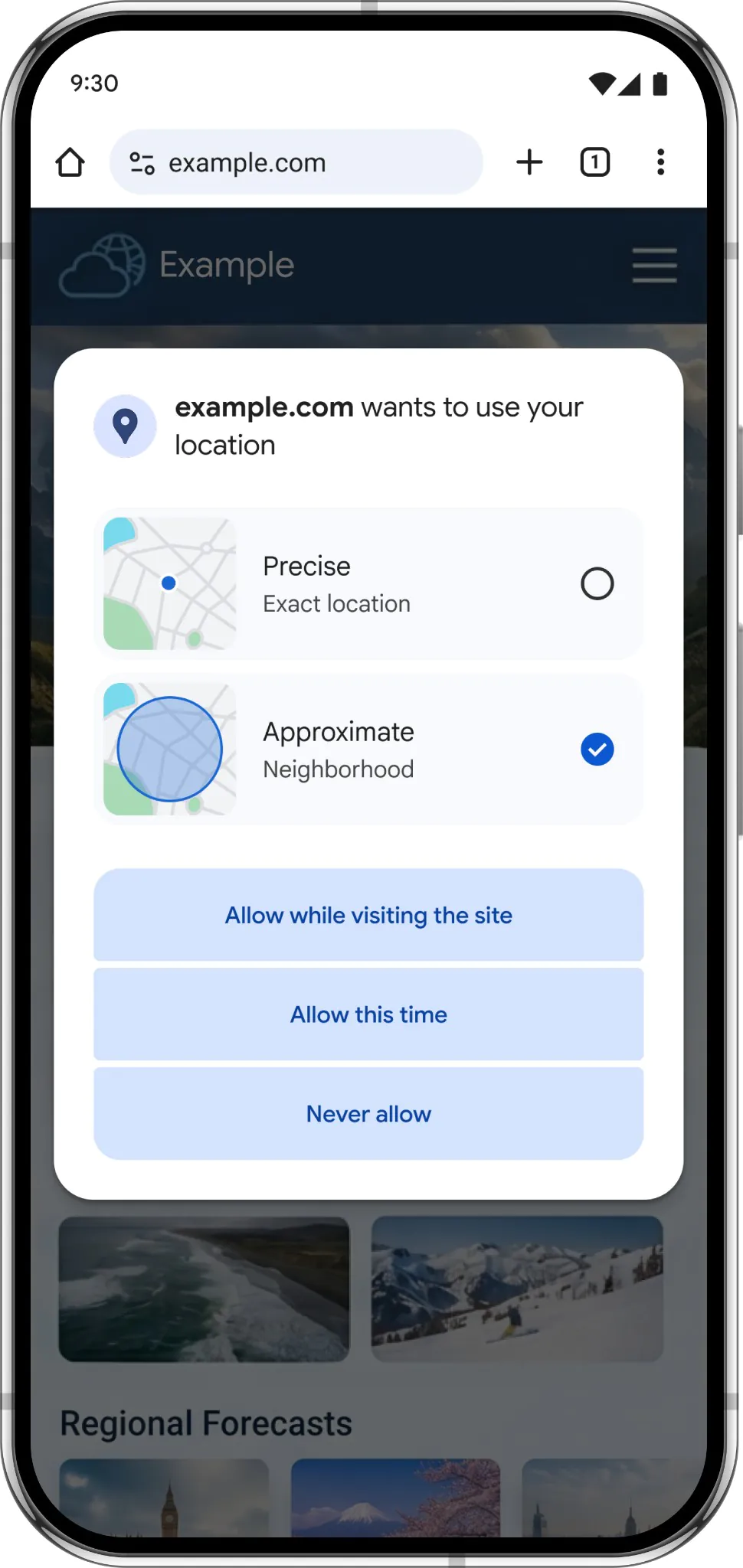
Точная геолокация будет также доступна. Она действительно нужна, например, при заказе еды, вызове такси или поиске ближайшего банкомата. Но для обычного просмотра сайтов часто достаточно примерного местоположения.
Пока функция доступна только в Chrome на Android. В дальнейшем Google планирует добавить такую возможность и в настольную версию браузера.
Изменение затронет и разработчиков сайтов. Google готовит новые API, которые позволят запрашивать именно примерную геолокацию или явно указывать, что сервису требуется точная. Компанию также призывает разработчиков не требовать координаты без реальной необходимости.



