







RAT-вредонос CannibalRAT используется в таргетированных атаках, как выяснили эксперты, этот зловред заимствует куски кода у других проектов с открытым исходным кодом. Специалисты Talos отметили две версии, которые используются в целевых атаках, — 3.0 и 4.0.
«Сам RAT не представляет собой сложную вредоносную программу, однако заимствует строки других программ. Командный центр вредоноса использует DNS-технику fast flux для того, чтобы оставаться скрытым», — пишут исследователи.
Два образца были написаны на языке Python и упакованы в исполняемый файл с помощью популярного инструмента py2exe. Эксперты отмечают, что версия 4.0 немного урезана, так как отсутствуют некоторые вредоносные функции. Судя по всему, авторы CannibalRAT пытались добавить методы обфускации, чтобы избежать обнаружения.
Версия 4.0 включает в себя функцию, которая будет генерировать случайные строки в памяти, это сделано, чтобы затруднить анализ вредоносной программы.
«Байт-код основного вредоносного скрипта хранится в PE-файле (Portable Executable, переносимый исполняемый) в секции PYTHONSCRIPT, также присутствует библиотека PYTHON27.DLL. Все остальные модули сжимаются и сохраняются в исполняемом оверлее», — продолжают исследователи.
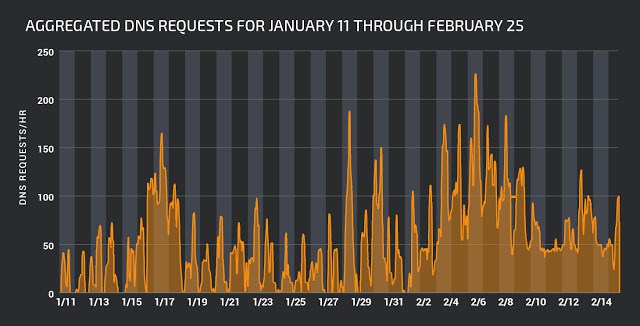
Первый вариант вредоноса был обнаружен 8 января, однако всплеск активности эксперты Cisco Talos отметили после выхода версии 4.0, которая была замечена 5 февраля 2018 года. Все варианты CannibalRAT используют обфускацию имен командных центров C&C, также они укореняются в системе, используя ключ реестра «CurrentVersion\Run», где создается служба «Java_Update».
После запуска CannibalRAT версии 4.0 создается файл PDF с встроенным HTML-кодом, который загружает изображение, размещенное на imgur.com, и запускает Chrome для открытия PDF-файла. Обе версии используют одни и те же серверы C&C, однако версия 3.0 использует стандартные веб-запросы, а более новая версия использует API на основе REST.
«Киберпреступники пытаются использовать технологию fast flux для сокрытия командных центров, имена серверов меняются с высокой частотой, а конечные точки, как правило, одинаковы, все они принадлежат провайдеру телекоммуникационных услуг в Бразилии, имеющему системный номер AS 7738», — объясняют специалисты.
Также эксперты отмечают, что CannibalRAT заимствует часть кода у Radium-Keylogger, исходный код которого публикован на Github, а функция обнаружения виртуальной машины была скопирована из другого репозитория Github.
CannibalRAT распространялся через ресурсы inesapconcurso.webredirect.org и filebin.net, второй является популярной платформой для обмена файлами, а вот первый домен был специально создан для вредоносной кампании.






