














Российским дата-центрам могут серьезно облегчить жизнь. Аналитический центр при правительстве подготовил проект дорожной карты «Гильотина 2.0», который предполагает масштабную зачистку нормативных барьеров для отрасли ЦОДов. Документ затрагивает более 15 законов и подзаконных актов.
Его главная идея проста: если стране нужны новые дата-центры, строить и эксплуатировать их должно быть проще.
Одно из ключевых предложений, по данным «Ведомостей», — официально выделить ЦОДы в отдельную категорию бизнеса. Для них хотят создать собственные коды ОКВЭД и закрепить дата-центры как отдельный вид использования земельных участков в градостроительной документации.
Также предлагается упростить выделение земель под строительство ЦОДов, прокладку кабельной инфраструктуры и переоборудование уже существующих зданий под серверные площадки.
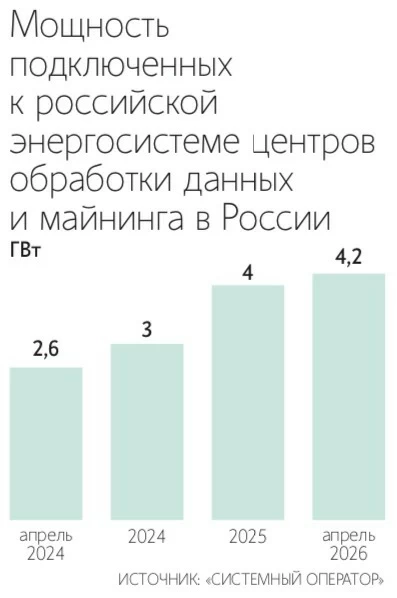
Отдельный блок посвящен энергетике. Для отрасли предлагают закрепить статус особо значимых потребителей электроэнергии и снять ограничения на подключение к единой энергосети для объектов с собственной генерацией мощностью свыше 25 МВт.
Еще одна инициатива касается пожарной безопасности. Для дата-центров хотят разработать специальные правила, учитывающие безлюдный режим работы машинных залов. Это может позволить отказаться от части традиционных требований, например обязательных систем водяного пожаротушения.
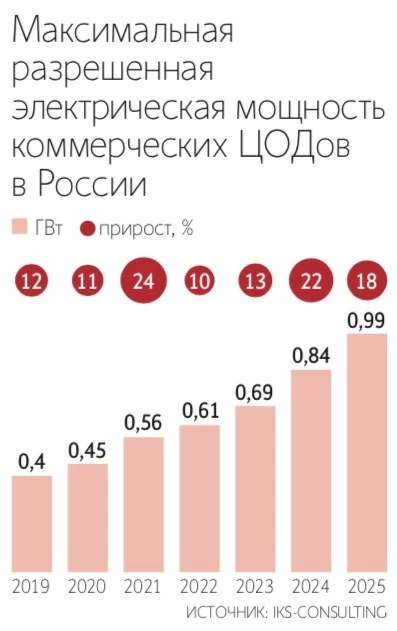
Изменения затронут и инвестиционные проекты. В реестр ЦОДов предлагается включать не только уже работающие объекты, но и строящиеся или проектируемые площадки. По оценкам авторов документа, это позволит сократить инвестиционный цикл на 6-12 месяцев.
Не забыли и про кадры. В дорожную карту включены предложения по созданию профильных образовательных программ и профессиональных стандартов для специалистов отрасли.
Впрочем, документ пока находится на стадии обсуждения. Источники на рынке отмечают, что часть инициатив еще может измениться. Но общий тренд уже очевиден: власти начинают воспринимать дата-центры как отдельную стратегическую отрасль, а не просто как разновидность объектов связи.



