







В паблик выложен код TotalRecall — инструмента, позволяющего автоматизировать кражу конфиденциальных данных из баз Recall. Запуск хайпового ИИ-помощника запланирован на 18 июня, и автор PoC хотел показать, насколько новая фича Windows ненадежна.
О появлении ИИ-функции в Windows 11 стало известно две недели назад: Microsoft анонсировала выпуск новой линейки компьютеров, Copilot+, и рассказала о нововведениях. Функция Recall вызвала бурную дискуссию — и специалисты по ИБ, и простые поклонники приватности заподозрили, что она небезопасна.
Новый механизм призван ускорить поиск нужной информации на компьютере. Каждые пару секунд он делает снимок экрана, фиксируя также действия юзера (например, уменьшение размера окна), шифрует и сохраняет локально. Параллельно Recall вычленяет все возможные ключи путем оптического распознавания и помещает их в базу SQLite в папке текущего пользователя.
Как оказалось, данные в этот файл записываются в открытом виде. Доступ к нему не требует привилегий уровня SYSTEM, а для просмотра даже не нужно админ-прав. С учетом того, что Recall будет включена по дефолту, ознакомиться с содержимым сможет любой другой пользователь.
Потестировав ИИ-функцию, известный эксперт Кевин Бомон (Kevin Beaumont) обнаружил, что собранную ею информацию можно вывести с помощью инфостилера. На его машине был установлен Microsoft Defender for Endpoint, который отреагировал на коммерческого вредоноса, но слишком поздно: за 10 минут тот успел украсть целевые данные.
Устойчивость новинки к злоупотреблениям проверил также специалист по offensive security Александер Хагенах (Alexander Hagenah). Его эксперимент подтвердил возможность автоматизации кражи данных, и исследователь решил опубликовать свой PoC-код, чтобы предупредить всех об угрозе.
Созданный им инструмент отыскивает базу данных Recall, копирует скриншоты и записи SQLite в свою папку, парсингом находит артефакты, заданные через ввод (пароли, реквизиты банковских карт и т. п.), и выдает короткий отчет:
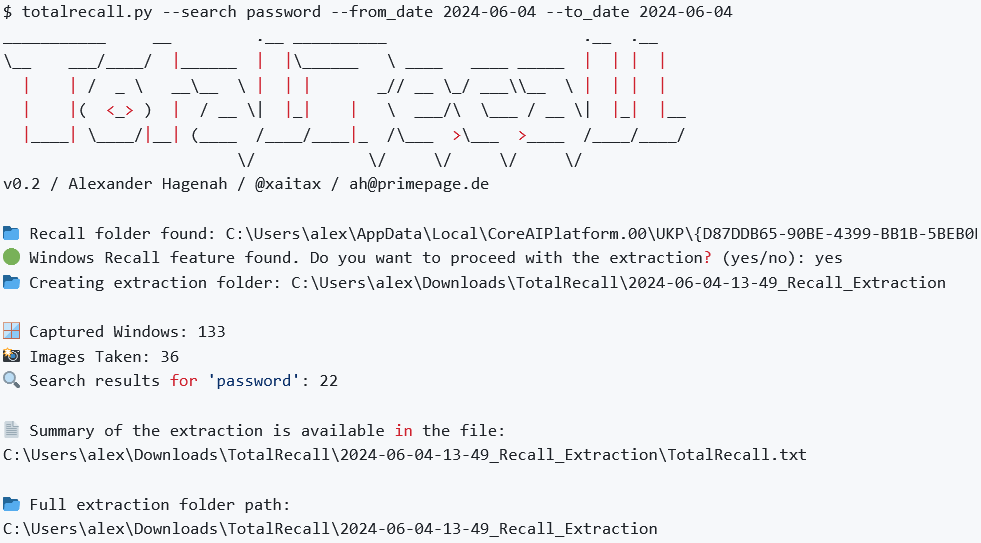
В ответ на вопрос Help Net Security Хагенах заявил, что вносить изменения в код TotalRecall он не планирует.
«PoC останется как есть. Мне просто безумно интересно, чем ответит Microsoft перед запуском Recall».






