








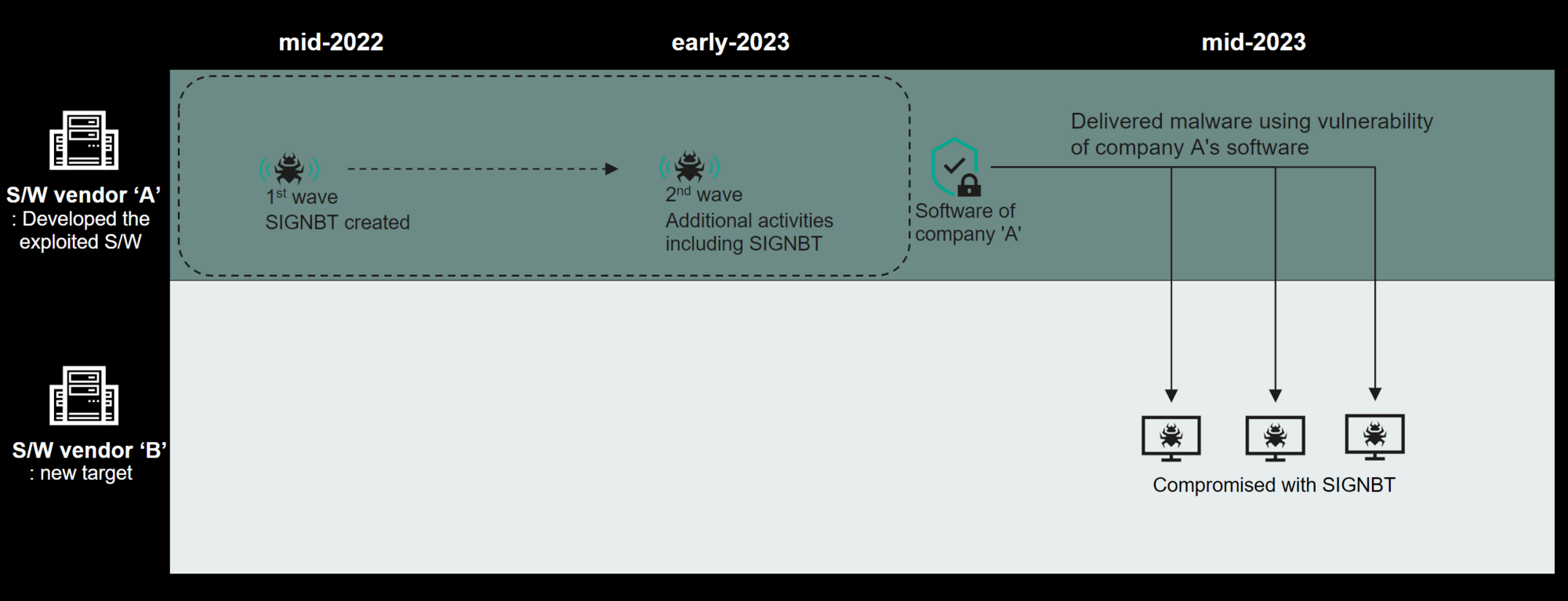
На конференции SAS в Таиланде «Лаборатория Касперского» представила результаты анализа новой киберкампании Lazarus. Злоумышленники атакуют представителей промышленного сектора, используя уязвимости в софте для шифрования веб-коммуникаций.
Патчи для этого продукта вышли давно, однако многие пользователи, как случается, продолжают довольствоваться версиями софта, в которых уязвимости не исправлены. Целью новых эксплойт-атак Lazarus является внедрение зловреда SIGNBT с функциями бэкдора для кражи учетных данных.
Развертывание вредоноса осуществляется с использованием техники DLL side-loading, позволяющей обойти защиту Windows. С его помощью в систему дополнительно загружаются инструмент профилирования жертв LPEClient, уже известный по прежним атакам Lazarus, а также утилиты для выгрузки учетных данных из памяти.

Как показал дальнейший анализ, злоумышленники несколько раз взламывали сети разработчика софта, служащего точкой входа в текущих атаках. Эксперты полагают, что Lazarus пыталась таким образом добраться до исходных кодов и вмешаться в цепочку поставок.
«Продолжающиеся атаки Lazarus — свидетельство того, что злоумышленники обладают серьёзными техническими возможностями и сильной мотивацией, — комментирует эксперт Kaspersky Сонгсу Парк (Seongsu Park). — Они действуют по всему миру, целясь в разные организации из промышленного сектора, и используют для этого разнообразные методы. Угроза сохраняется и постоянно эволюционирует, что требует особой бдительности».
Защититься от целевых атак помогут рекомендации «Лаборатории Касперского»:
- регулярно обновлять ОС, приложения и защитный софт;
- обучать сотрудников с осторожностью относиться к электронным письмам, сообщениям или звонкам, в которых просят сообщить конфиденциальную информацию;
- проверять личность отправителей перед тем, как передавать им свои данные или переходить по подозрительным ссылкам;
- использовать надёжное решение для защиты рабочих мест, такое как Kaspersky Security для бизнеса;
- обеспечить доступ к базе данных об угрозах (threat intelligence) специалистам SOC-центра;
- повышать уровень знаний ИБ-команды с помощью тренингов;
- использовать EDR-решения для обнаружения угроз на конечных устройствах, расследования и своевременного восстановления после инцидентов.






