







Киберпреступная группировка, которую отслеживают под именем Prolific Puma, предоставляла другим злоумышленникам сервис для сокращения ссылок. На протяжении четырёх лет Prolific Puma удавалось оставаться незамеченной.
По данным исследователей, менее чем за месяц кибергруппа зарегистрировала тысячи доменов, многие из которых были доменами верхнего уровня США (usTLD) и помогали реализовать фишинговые схемы, рассылать спам и распространять вредоносные программы.
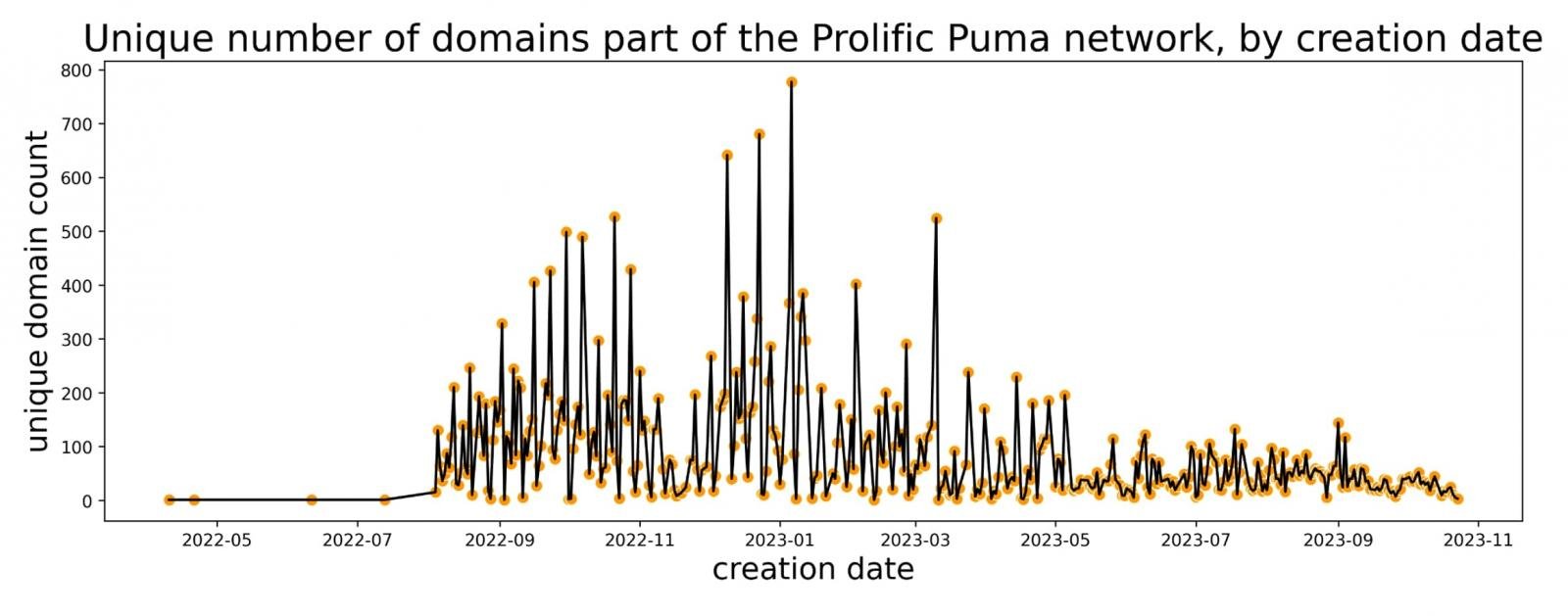
Специалисты Infoblox впервые зафиксировали активность Prolific Puma около полугода назад. Сначала экспертам попались домены, сгенерированные при помощи RDGA (registered domain generation algorithm) и задействованные для сервиса сокращения URL.
Исследователи смогли отследить вредоносную сетевую активность, которая, как выяснилось, использовала usTLD. Из-за принципа работы сервисов сокращения ссылок Infoblox смогла отследить сами короткие URL, но не целевые веб-страницы.
«В конце концов нам удалось ухватиться за несколько коротких ссылок, которые выводили нас на конечные страницы. Это оказались фишинговые и скамерские сайты», — пишут специалисты.
Кстати, лишь ряд ссылок ввёл прямо на страницу, другие — осуществляли множество редиректов. Более того, в отдельных случаях через такой URL пользователь попадал на CAPTCHA.
Именно такой разброс подходов навёл исследователей на мысль о том, что сервис сокращения ссылок используют разные киберпреступники. С апреля 2022 года Prolific Puma удалось зарегистрировать около 75 тысяч уникальных доменов.
Как правило, эти домены — буквенно-цифровые и псевдослучайные, а также различаются по размеру:
| TLD | us | link | info | com | cc | me |
|---|---|---|---|---|---|---|
| Domains | vf8[.]us 2ug[.]us z3w[.]us yw9[.]us 8tm[.]us |
cewm[.]link wrzt[.]link hhqm[.]link ezqz[.]link zyke[.]link |
uelr[.]info ldka[.]info fbvn[.]info baew[.]info shpw[.]info |
kfwpr[.]com trqrh[.]com nhcux[.]com khrig[.]com dvcgg[.]com |
jlza[.]cc hpko[.]cc ddkn[.]cc mpsi[.]cc wkby[.]cc |
scob[.]me xnxk[.]me zoru[.]me mjzo[.]me ouzp[.]me |
На видео ниже можно посмотреть сервис Prolific Puma в действии:






