













Исследователи из ESET обнаружили новую версию Android-зловреда NGate, на этот раз он маскируется не под NFCGate, как раньше, а под легитимное приложение HandyPay. По данным ESET, активность началась ещё в ноябре 2025 года. Пользователей заманивают на поддельные страницы, имитирующие карточку приложения в Google Play.
Дальше жертве предлагают скачать «нужное» приложение, которым и оказывается троянизированная версия HandyPay. После установки программа просит сделать её приложением для оплаты по умолчанию, а затем убеждает ввести ПИН-код карты и приложить её к смартфону с NFC.
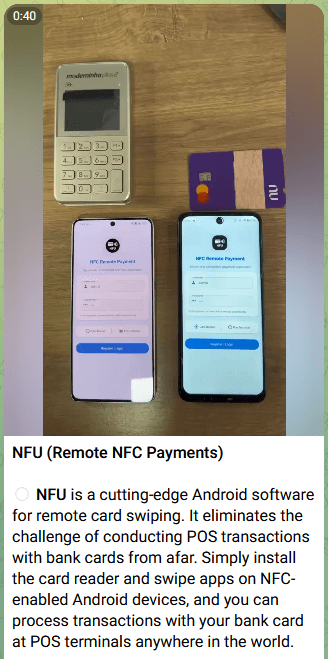
На этом этапе и начинается основная атака. Зловред перехватывает NFC-данные банковской карты и передаёт их на устройство злоумышленников. Параллельно он крадёт введённый пользователем ПИН-код и отправляет его на командный сервер. В итоге у атакующих оказывается всё, что нужно для бесконтактного снятия наличных в банкомате или несанкционированных платежей.
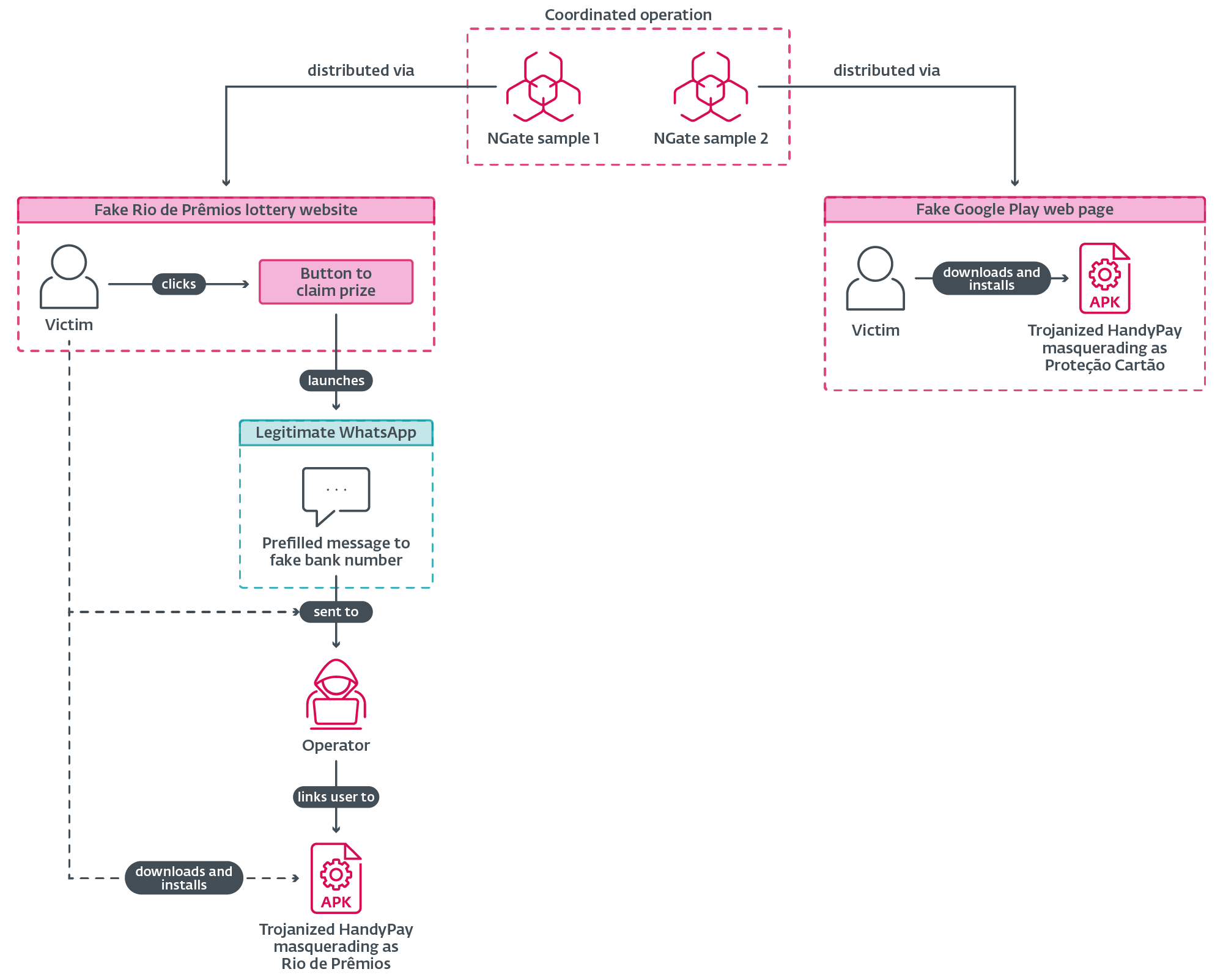
По сути, перед нами очередная эволюция NGate — семейства зловредов, которое ESET впервые подробно описала ещё в августе 2024 года. Тогда речь шла об атаках на клиентов чешских банков с использованием NFC-релейных атак для кражи данных платёжных карт и последующего вывода денег через банкоматы.
Новая версия отличается не только географией, но и инструментарием. Вместо старых решений злоумышленники выбрали HandyPay — приложение с уже встроенной функцией релейной передачи NFC-данных.
В ESET считают, что это могло быть связано и с более низкой стоимостью использования такого инструмента, и с тем, что HandyPay не требует лишних разрешений, кроме статуса платёжного приложения по умолчанию. Это делает атаку менее подозрительной для жертвы.
Есть у этой истории и ещё одна любопытная деталь. Исследователи заметили в коде эмодзи в отладочных и системных сообщениях — это может указывать на использование генеративного ИИ при создании или доработке вредоносной нагрузки. Прямого доказательства тут нет, но сама версия выглядит вполне в духе времени: преступникам уже не обязательно быть сильными разработчиками, чтобы собирать рабочие зловреды.



