








Специалисты в области кибербезопасности рассказали о новом векторе атаки, строящемся на использовании некорректной конфигурации TLS-серверов. В случае успешной эксплуатации злоумышленники могут перенаправить HTTPS-трафик браузера жертвы на другой IP-адрес и потенциально украсть конфиденциальную информацию пользователя.
Сама форма атаки получила имя ALPACA (сокращение от «Application Layer Protocol Confusion - Analyzing and mitigating Cracks in tls Authentication»). Её обнаружили эксперты Рурского Мюнстерского и Падерборнского университетов.
«Атакующие могут перенаправить трафик от одного поддомена другому, при этом сохранится валидная TLS-сессия. Такие вот кросс-протокольные атаки возможны в том случае, когда некорректное поведение одного из сервисов вызывает компрометацию другого протокола прикладного уровня», — говорится в исследовании специалистов.
Как объяснили исследователи, ALPACA существует из-за того, что TLS не привязывает TCP-соединение к протоколу прикладного уровня. Другими словами, это неспособность TLS защитить подлинность TCP-соединения.
Если взять клиент (браузер пользователя) и два сервера приложений, задача вырисовывается следующая: заставить запасной сервер принять данные от клиента и наоборот. При этом клиент использует специальный протокол для открытия защищённого канала (скажем, HTTPS) при взаимодействии с целевым сервером, а подставной сервер может задействовать другой протокол (скажем, FTP) — такие атаки и называются кросс-протокольными.
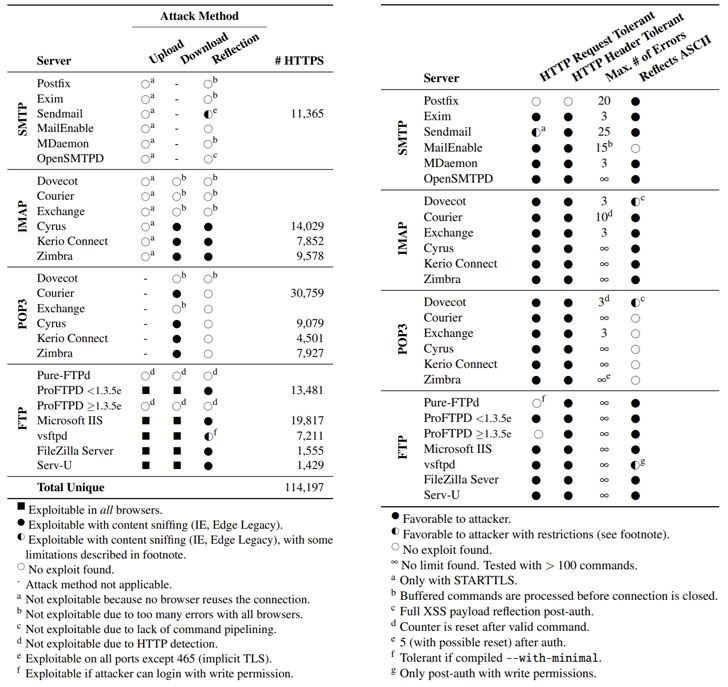
Бороться с кросс-протокольными атаками эксперты предлагают расширениями Application Layer Protocol Negotiation (ALPN) и Server Name Indication (SNI). Дополнительную информацию относительно ALPACA исследователи обещают представить на конференции Black Hat USA 2021 в этом году. Также можно изучить соответствующий код на GitHub.






