







Некоторые браузеры до сих пор допускают атаки вида «drive-by-download» даже из, казалось бы, защищённых мест вроде ифреймов (iframes), изолированных в песочнице. Напомним, что при drive-by-download загрузка вредоносного файла происходит автоматически при посещении сайта (без всякого взаимодействия с жертвой).
Как правило, атакующие используют этот метод, чтобы подсунуть пользователю потенциально опасные или откровенно вредоносные программы. Расчёт на то, что невнимательная жертва запустит скачанный файл.
Новый отчёт исследователей из компании Confiant показывает, что даже защищённая среда вроде изолированных ифреймов не защитит пользователя от drive-by-download при веб-сёрфинге.
Именно с этим столкнулись посетители сайта Boing Boing в январе. За drive-by-download отвечал вредоносный JavaScript-код, внедрённый в страницу взломанного ресурса. В результате этот код размещал на сайте ссылку, которая инициировала загрузку злонамеренного содержимого безо всякого участия пользователя.
После этого исследователи заинтересовались реализацией этого метода в случае с изолированными ифреймами. К счастью, как выяснили специалисты, тот же Chrome 83 блокировал подобные загрузки.
Microsoft Edge, который в качестве базы отныне использует Chromium, тоже показал себя неплохо. У Mozilla Firefox дела идут чуть хуже — браузер не блокирует кросс-сайтовые ифреймы и выдает диалоговое окно для загрузки файла.
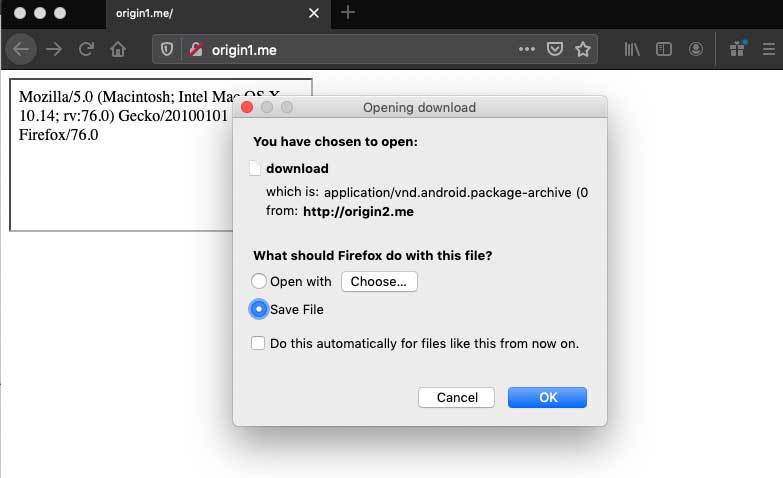
Brave тоже не смог заблокировать загрузку потенциально вредоносного содержимого. Safari также пытается загрузить предложенный файл, однако в ходе тестирования браузер от Apple так и не смог довести дело до конца.






