













Фотография с ключами в руке может оказаться не такой милой, как кажется. Специалист по кибербезопасности Эван Оттингер показал, что по обычному снимку ключа из соцсетей можно сделать рабочую копию, для этого не нужна лаборатория злодея из кино.
Оттингер — типичный ред тимер, по заказу компаний имитирует реальные атаки, проверяет защиту сетей и иногда даже физическую безопасность зданий.
По его словам, люди постоянно выкладывают фото ключей — от обычных пользователей до знаменитостей. А зря.
Если на фотографии хорошо виден профиль и нарезка ключа, их можно проанализировать, восстановить геометрию и изготовить копию. Оттингер использовал открытые инструменты для декодирования ключей, графический редактор и 3D-принтер. В итоге эксперимент сработал: пластиковый ключ, напечатанный по данным со снимка, оказался пригоден для открытия замка.
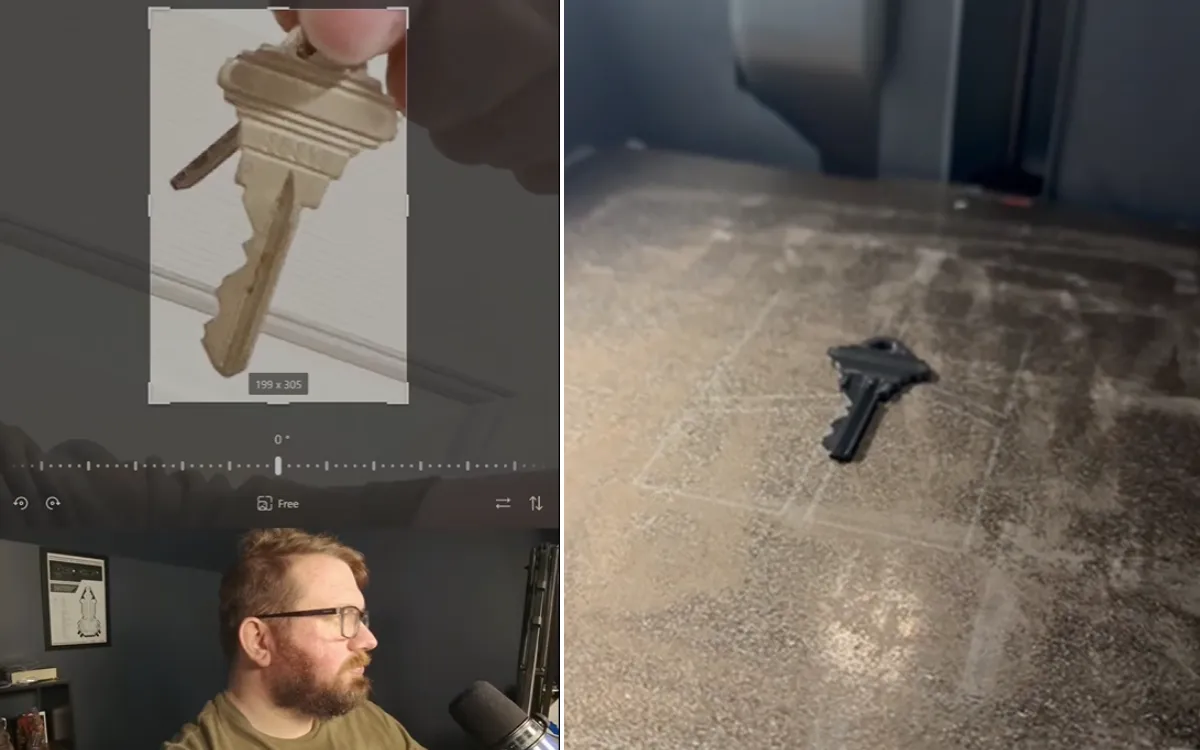
Сам исследователь признаёт, что сначала тоже сомневался: «Да ладно, не может же это реально работать?» Оказалось, что может. Более того, для подготовленного человека весь путь от скачанного фото до готового ключа может занять около 10-15 минут.
Главная проблема в том, что такой способ не похож на взлом в привычном смысле. В отличие от отмычек, использование копии ключа не оставляет очевидных следов на замке. Для прохожих всё выглядит нормально: человек просто открыл дверь своим ключом. Именно такие сценарии, по словам Оттингера, и заставляют специалистов по безопасности нервничать.
Ключи нужно воспринимать как пароли. Их не показывают крупным планом, не выкладывают в сторис и не держат перед камерой ради красивого поста. Если очень хочется поделиться радостью о новом доме, лучше закрыть зубцы ключа рукой, размыть их или вообще сфотографировать брелок.
Оттингер также советует не полагаться только на один замок. Камеры, сигнализация и другие уровни защиты делают дом менее удобной целью.



