










Телеграм-канал «Провод» опубликовал историю одного из пользователей, который решил проверить, что происходит с его MacBook. Судя по опубликованному скриншоту, главным подозреваемым в загрузке процессора оказался российский мессенджер МАКС.
По словам автора, приложение умудрилось загрузить процессор почти до предела.
В статистике системы указано, что процесс МАКС потреблял до 94% одного ядра процессора. Для сравнения, большинство популярных мессенджеров обычно ограничиваются нагрузкой в пределах 10-30%.
Пользователь утверждает, что приложение продолжало расходовать заряд аккумулятора и нагревать устройство даже в фоновом режиме. Согласно данным системного мониторинга, за время работы МАКС накопил около 33 часов фоновой активности.
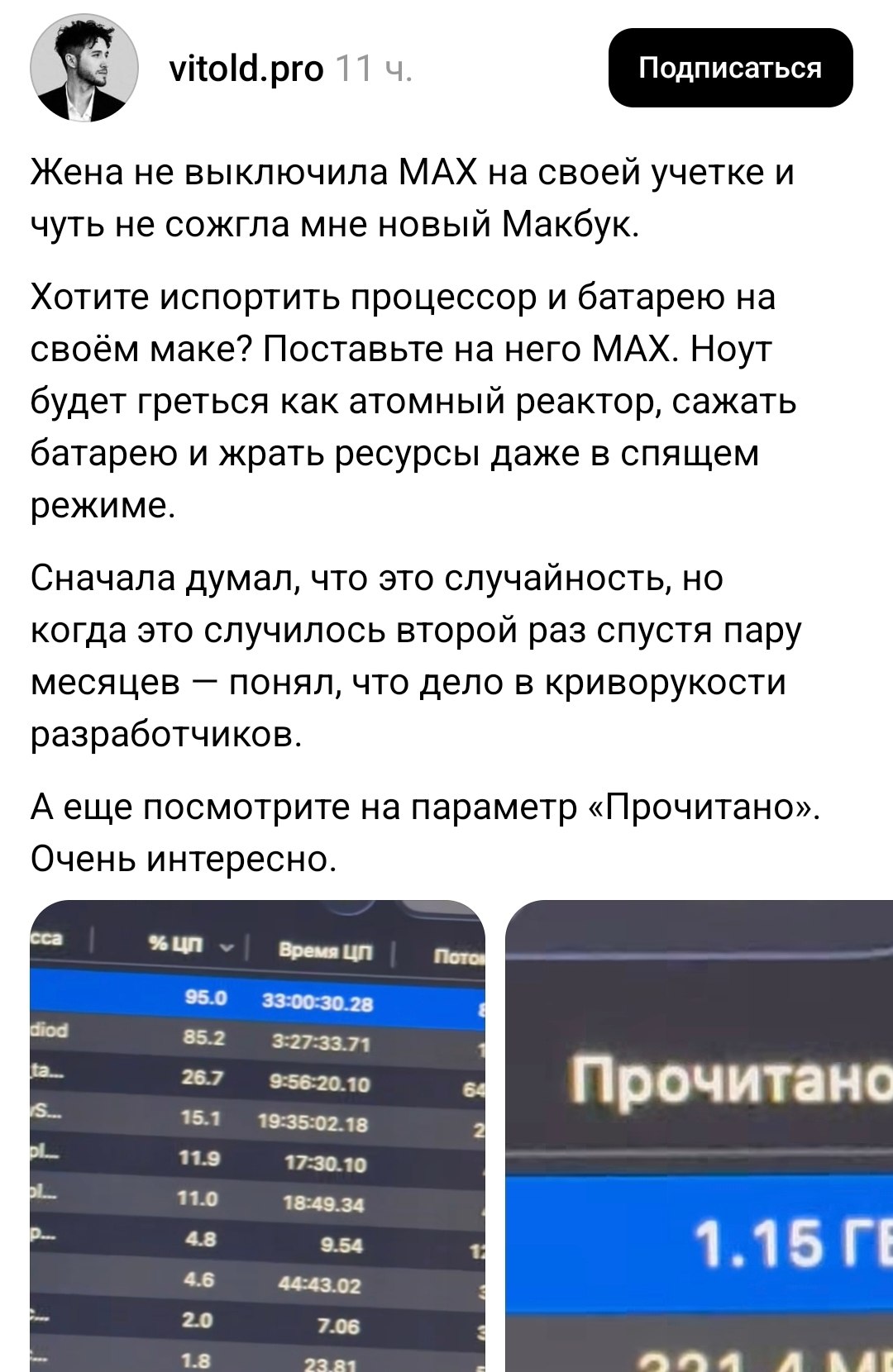
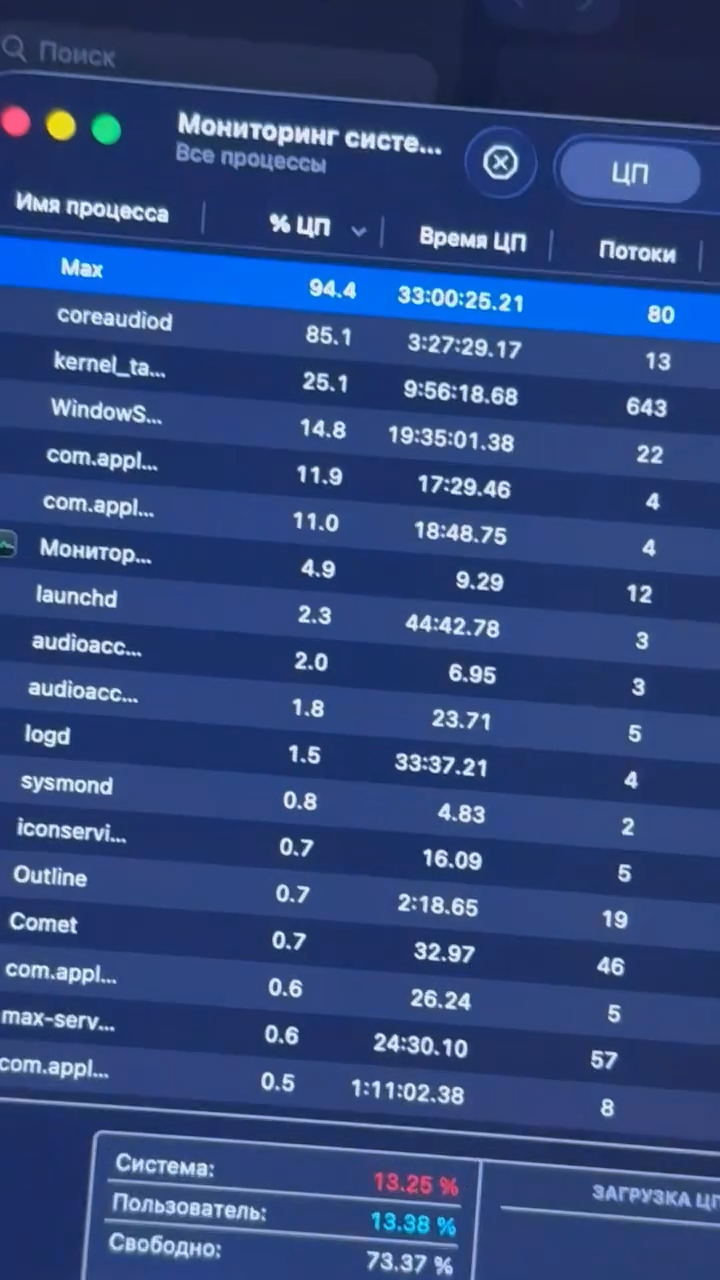
Особое внимание автора привлекла ещё одна цифра — более 1,15 ГБ данных, прочитанных приложением с диска. Что именно мессенджер так активно считывал, остаётся неизвестным.
Впрочем, пока речь идёт лишь об отдельных сообщениях пользователей. Разработчики МАКС ситуацию официально не комментировали, а независимого технического анализа работы приложения на момент публикации не появилось.



