















Security Vision выпустила обновление своей платформы. В новой версии появилась поддержка OpenID Connect, инструменты для проверки зависимостей между объектами, а также несколько небольших изменений в отчётах и чатах. Поддержка OIDC расширяет варианты подключения платформы к корпоративным системам аутентификации.
Организации смогут использовать уже настроенную инфраструктуру управления учётными записями и единым входом.
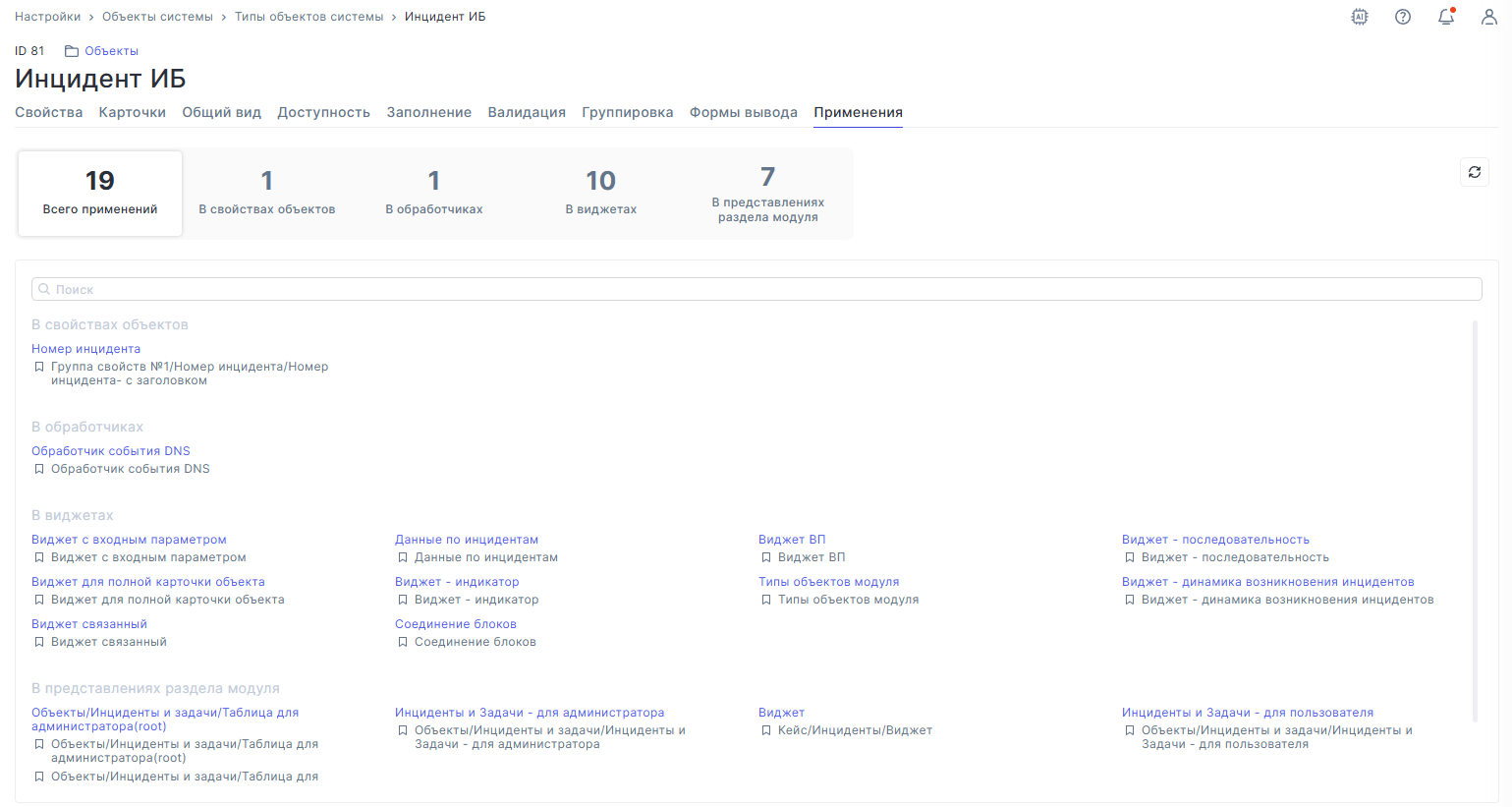
В настройках типов объектов появилась вкладка «Применения». В ней можно посмотреть, где именно в платформе используется выбранный тип объекта. Это пригодится перед изменением конфигурации: администратор сможет заранее оценить, какие связанные настройки могут быть затронуты.
Разработчики также переработали историю запуска отчётов. Элементы для просмотра входных параметров и выгрузки готового отчёта теперь расположены удобнее, поэтому найти настройки предыдущего запуска и его результат должно быть проще.
В чатах карточек объектов добавили регистронезависимый поиск сотрудников при упоминании. Теперь имя пользователя будет находиться независимо от того, с заглавной или строчной буквы его ввели.
Есть и техническое изменение, которое важно учесть перед обновлением. Для работы коннектора PowerShell теперь требуется PowerShell версии 7.4.16. Если в инфраструктуре используется более ранняя версия, её придётся обновить заранее.
В целом релиз получился без громких перестроек: основные изменения касаются доступа, контроля связанных настроек и повседневной работы с отчётами и обсуждениями.



